Skip to content
Domains
Enterprise AI Deployment
Life Sciences & Healthcare
Private Equity & Portfolio Value Creation
Case Studies
Blog
About
Contact Us
Domains
Enterprise AI Deployment
Life Sciences & Healthcare
Private Equity & Portfolio Value Creation
Case Studies
Blog
About
Contact Us
The blog
Sigmoidal Signals
Writing from the team on research, engineering, and the frontier of enterprise AI.
Articles
Search articles
All
Generative AI
RAG
AI Strategy
Ethical AI
Project Lifecycle
Archive
Generative AI
Jan 1, 2024
Explore the Horizon of Possibilities: Access the Comprehensive Report on Current Market Applications of Generative AI
Read
Generative AI
Nov 2, 2023
GenAI Risks Your Business Can't Afford to Roll the Dice On
Read
Ethical AI
Oct 18, 2023
Don’t let 81% of enterprise companies outrun yours with an internal generative AI team
Read
AI Strategy
Oct 16, 2023
Five Ways Businesses Are Using AI to Their Advantage
Read
RAG
Oct 4, 2023
Embrace the Next-Gen of Business with AI Knowledge Assistants
Read
RAG
Sep 27, 2023
Full Power of Custom Data Integration in RAGs
Read
AI Strategy
Sep 13, 2023
Is Your Company Ready to Join the 75% Making the Next-gen Shift by 2024?
Read
Generative AI
Aug 28, 2023
Is Your AI Thinking Outside the Box?
Read
Generative AI
Aug 17, 2023
Secure Over 83% of Customers Strictly by Embracing AI Compliance
Read
Project Lifecycle
Jul 27, 2023
This Is Why 85% of Machine Learning Projects Fail
Read
RAG
Jul 21, 2023
Revolutionize Documents Generation, Market Research with AI
Read
AI Strategy
Jun 20, 2023
Be the Business in the 57% Succeeding, Not the 43% Worried about AI!
Read
Archive
Jun 25, 2020
AI Solutions Against Bias and Discrimination: Do 2020 Machines Give a New Chance for Humanity?
Read
Archive
Jun 24, 2020
Why Are Chatbots Cool, and Where Are They Headed?
Read
Archive
Jun 24, 2020
What Is Natural Language Processing (NLP)?
Read
Archive
Jun 24, 2020
Natural Language Processing vs. Machine Learning vs. Deep Learning
Read
Archive
Jun 24, 2020
A Survey of the Latest Chatbot APIs
Read
Archive
Jun 19, 2020
Online Word2Vec for Gensim
Read
Archive
Jun 18, 2020
Understanding Your Data: Basic Statistics
Read
Archive
Jun 17, 2020
The Math Behind Lucene
Read
Archive
Jun 17, 2020
All About That Bayes: An Intro to Probability
Read
Archive
Jun 17, 2020
Build Your Own Search Engine
Read
Archive
Jun 3, 2020
Fuzzy Matching: A Simple Trick
Read
Archive
May 12, 2020
Additive Attention in PyTorch: Implementation
Read
Archive
May 7, 2020
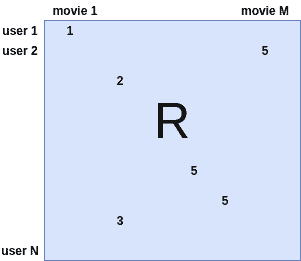
Recommender Systems, Part 1
Read
Archive
Apr 28, 2020
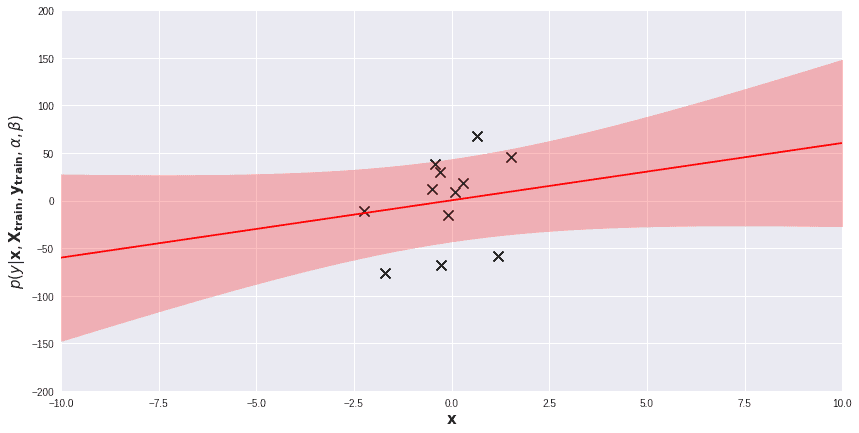
Interpreting Uncertainty in Bayesian Linear Regression
Read
Archive
Apr 21, 2020
AI Business Tools Making an Impact in 2020
Read
Archive
Mar 24, 2020
Where Syntax Ends and Semantics Begin. Why Should We Care?
Read
Archive
Mar 18, 2020
AI for Event-Driven Stock Prediction: Activist Investors
Read
Archive
Mar 5, 2020
AI in Investment Management Spots Event-driven Opportunities That Others Missed
Read
Archive
Feb 14, 2018
6 Jobs That Could See an Uptick in Demand With the Rise of AI: VentureBeat Article
Read
Archive
Feb 8, 2018
Natural Language Processing Algorithms (NLP AI)
Read
Archive
Dec 21, 2017
Portfolio Analysis by Machine Learning
Read
Archive
Dec 21, 2017
Use Case: Investment Opportunities Discovery
Read
Archive
Dec 21, 2017
Financial Times: Wall Street and AI (An Article)
Read
Archive
Dec 21, 2017
Artificial Intelligence and Machine Learning for Healthcare
Read
Archive
Nov 28, 2017
8 Machine Learning Terms Every Manager Should Know
Read
Archive
Nov 28, 2017
Artificial Intelligence Pharma: Drug Side-effect Detection
Read
Archive
Nov 24, 2017
Customer Clustering Using Artificial Intelligence
Read
Archive
Nov 3, 2017
Machine Learning in Business: Free Up 3 Hours per Day
Read
Archive
Nov 3, 2017
Machine Learning for Trading: Topic Overview
Read
Archive
Nov 3, 2017
Docker Deep Learning: GPU-Accelerated Keras
Read
Archive
Nov 3, 2017
Docker Swarm: How and When to Use It?
Read
Archive
Nov 3, 2017
Object Detection Deep Learning
Read
Archive
Nov 3, 2017
How Does AlphaGo Work? Power of Reinforcement Learning
Read
Archive
Nov 3, 2017
AI Advertising & RTB: How AI Knows Your Shoe Size
Read
Archive
Oct 16, 2017
AI in Finance: New Applications for High ROI in 2020
Read
Archive
Oct 10, 2017
Deep Learning Chatbot: Analysis and Implementation
Read
Archive
Sep 27, 2017
Recommendation Systems: How Companies Are Making Money
Read
Archive
Sep 8, 2017
Variational Dropout: Uncertainty in Deep Learning?
Read
Archive
Sep 5, 2017
GAN Deep Learning Architectures: Review
Read
Archive
Aug 18, 2017
Data Science Events: Celebrating 2048 Members
Read
Archive
Aug 15, 2017
Elasticsearch: 10 Tips to Get Started
Read
Archive
Jun 20, 2017
Data Science Consulting Questions to Ask Before Hiring
Read
Archive
Apr 11, 2017
SSLForFree: Setting Up SSL with NGINX and Let's Encrypt
Read
Archive
Apr 5, 2017
IoT World Santa Clara: Meet the Sigmoidal Team
Read
Archive
Apr 5, 2017
Git Hooks: Automatic Code Quality Checks
Read
Archive
Mar 30, 2017
Jupyter Notebook Shortcuts Explained
Read
Archive
Mar 24, 2017
TensorFlow AWS Setup: Proper Setup of Version 1.0
Read
Archive
Mar 24, 2017
Machine Learning Pipeline: You've Got It Wrong
Read
Archive
Jan 10, 2017
How to Automatically Fill PDF Forms Using Python and pdfrw
Read