AI Solutions Against Bias and Discrimination: Do 2020 Machines Give a New Chance for Humanity?

Human history has an unfortunate record of discrimination and biases against each other that follow us from ancient times. A conscious effort towards developing inclusive and equal social systems is a necessity. In the increasingly automated world, where computers interact with humans, Artificial Intelligence gives us another shot at making the world a fairer place with equal opportunities.
However, machines are built by people. We are obliged to put conscious effort into making sure the AI solutions won’t carry over our mistakes.
The appeal of AI is tremendous: it can search through millions of pieces of data and use it to make forecasts that are often more accurate than ours. Automating processes with AI also seems more objective than relying on subjective (and slower) human analysis. After all, the AI algorithm will not “dislike” your picture or assume anything based on it, especially when it is taught to ignore it completely.
The problem is, AI algorithms are not necessarily human-bias free. AI is designed and trained on human data, and human thinking is characterized by bias. Therefore bias is also a built-in byproduct of human-designed systems. These AI biases can echo problematic perceptions, such as the perceived superiority of certain groups. Even well-designed AI systems can still end up with a bias, entirely by accident.
The question is: can we prevent AI from being racist and sexist? And if we can, then could machines help us create a fairer society?
People and biases
Let’s start from the beginning: before the machines were biased, people were. Why is that? According to the Cambridge Dictionary, bias is “the action of supporting or opposing a particular person or thing in an unfair way, because of allowing personal opinions to influence your judgment.”
Biases can be innate or learned. People may develop biases for or against an individual, a group, or a belief. It does not have to be limited to ethnicity and race; it is also gender, religion, sexual orientation, and many other characteristics that are subject to bias.
Are all biases conscious?
There are two types of bias: conscious (also known as explicit bias) and unconscious (also known as implicit bias). The conscious bias refers to the attitude we have on a conscious level, and most of the time, it arises as the direct result of a perceived threat.
The unconscious bias is a social stereotype about certain groups of people that a person forms outside their conscious awareness. It is automatic, unintentional, deeply ingrained, and able to influence behavior. Unconscious bias is more prevalent than the conscious one.
According to the American Psychological Association, only a small proportion of Americans today are explicitly racist and feel hatred towards other ethnicities and races.
But the majority of Americans, because they have grown up in a culture that has been historically racist in many ways and because they’re exposed to media that are biased, associate violence, drugs, and poverty with specific groups.

People will always be biased to some extent because their opinions are subjective and, what is worse, humans tend to generalize. This is partly the fault of the way we are programmed, and partly the failure of the way we programmed our society and culture. Does it mean machines have to be programmed like this as well?
Want to build a racist AI solution? Just hand it a newspaper
Obviously, AI solutions have no political agenda of their own, right? They’re not going to be intentionally racist unless they have explicitly been trained to be. It is also not (most of the time, at least) a political agenda of their creators that is the issue. The problem is that it is very easy to train machines to be racist by accident and without even trying.
Here are a few examples of how algorithms can discriminate on different fields based on race:
- Image Recognition: Researchers from Georgia Institute of Technology tested eight image-recognition systems used in self-driving cars, after observing higher error rates for specific demographics. They found their accuracy proving five percent less accurate on average for people with darker skin. So a self-driving car is more likely to run over a black person than a white one.
- Healthcare: An algorithm used in US hospitals to allocate healthcare for patients has been systematically discriminating against black people. A study concluded that the algorithm was less likely to refer black people than white people who were equally sick to programs that aim to improve care for patients with complex medical needs.
- Criminal Cases: In 2016, ProPublica published an investigation on an ML program that is used by courts to predict future criminals, and they found out that the system is biased against black people. The program learned about who is most likely to end up in jail from incarceration data. And historically, the criminal justice system has been unfair to black Americans. So when an AI program was fed with these historical data, it learned from biased decisions historically made by humans.
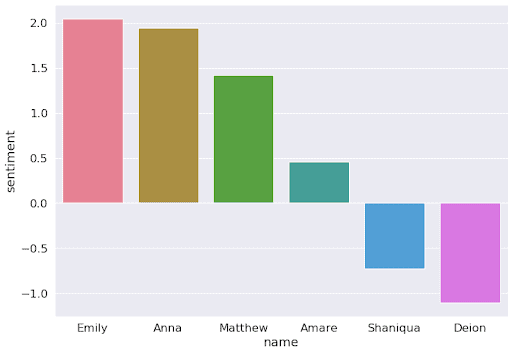
- Natural Language Processing (NLP): There is a broad spectrum of cases (for example, work/college admissions or even loan applications), where words can serve as an input: the so-called word embeddings represent words as inputs to machine learning. But there is a fairness problem when an algorithm learns the meaning of words from humans. Our opinions are often subjective and biased, so the meaning of the words (e.g., people names) is then biased. A paper in Science from 2017 found out that when a computer teaches itself English by crawling the internet, it becomes prejudiced against black Americans and women. For example, when the GloVe news dataset is used, the sentiment (how positive a given sentence is) of simple text starting with ‘My name is…’ is significantly lower when it ends with common names of black people than common names for white people.


How can we fight it?
Bias-free AI can soon be a powerful tool to tackle social issues, such as enhancing social mobility through fairer access to the financing/healthcare system, mitigating exclusion and poverty through making the judiciary systems more objective, bias-free testing in university admissions, and much more. We should expect fair AI solutions from both technology companies and authorities.
Military and tactics books say that weapons or tactics should always take into consideration the enemy strategy. That is also true for this particular fairness and human dignity fight. In the case of this war, there are also different ways to fight racial bias, depending on the domain (field) and the data used by the algorithm.
Image Recognition
In the case of image-recognition systems, the reason for bias is that training data that machines use for learning contain mostly samples gathered from white people. These AI solutions can have problems with recognizing people of different races because it simply did not see enough pictures of them. The effect is doubled when it comes to women of color.
Face recognition systems from the leading companies failed during the man/woman classification of Oprah Winfrey, Michelle Obama, and Serena Williams.
The biggest problem here is that face-recognition systems are widely used by law enforcement and border control. If the application has high false-positive rates for a specific group (and according to NIST study, a majority of the face recognition algorithms used in the US performed worse on nonwhite faces), it puts this population at the highest risk for being falsely accused of a crime.

The solution (our weapon) for this problem is quite simple. Still, it requires more attention during dataset preparation: the equal representation of people of color and gender in training datasets (e.g., face recognition) is crucial for algorithms (like face recognition ones) to work with the same precision regardless of race or gender.
Moreover, from the sociological point of view, those bias problems would be hard to overlook and natural to point out if minority representatives would be more encouraged to be a part of the artificial intelligence team.
Biases in AI solutions for Healthcare
The reason millions of black people were affected by racial bias in health-care algorithms? It was based on the historical cost of health care, where higher health-care costs are associated with greater needs. People who did have higher-cost treatment were assumed to need more extensive care, which seemed just about right. Or did it?

The biggest problem with this approach was the fact that those less wealthy simply couldn’t afford more extensive treatment, so they chose less expensive options, while their actual needs remain the same as people in the same condition who could opt for the more expensive ones.
The approximation of the healthcare needs by the amount of money spent on treatment was actually an exclusive approach, biased towards more wealthy people. Finding other variables than the cost of treatment to estimate a person’s medical needs reduced bias by 84%.
College Admissions
The problem here is often not testing actual skills but rather candidate background (e.g., childhood environment). If you have two candidates and one comes from the wealthy neighborhood and the other from a poor one, there is a possibility that the second one will score lower because she (or he) had the lower probability of gathering the certain knowledge assumed in the question, but it does not mean that she (or he) lacks needed skills.

The solution here is building classifiers powered by NLP whose role is early detection of biased questions based on the past applicants’ results. It would allow the preparation of a fair and inclusive set of questions during the admission/recruitment process for testing actual candidates’ skills, not their environmental background.
What exactly makes NLP systems biased?
The word embeddings technique is one of the most popular of Natural Language Processing methods and one of the most powerful ones.
It transforms actual words into mathematical vectors, which are later used as features in many predictive algorithms. It can be used for the analysis of job or loan applications to speed up these processes (and make them less subjective).
The problem is, these word embeddings can be easily biased because of the features of the actual human-generated internet data, from which they learn. Humans’ opinions are often subjective and biased, so the meaning of the words is then biased too.
From the perspective of the word embeddings algorithm, the easiest approach would be to gently ask humans to stop being racist and start producing less exclusive content. But even then, it would be hard to fight some indirect frequent word co-occurrences including historical, language ones, and even benevolent stereotypical ones.
For example, the association of female gender with any word, even a subjectively positive one such as attractive, can cause discrimination against women. The reason is, it can reduce their association with other terms, such as professional.
The actual ML approach to this problem seeks debiasing of word meanings (word embeddings) rather than skin-color neutralization (or softening) so that gender-neutral and race-neutral words are semantically equidistant to all human races (similarly as debiasing of gender described in this article).
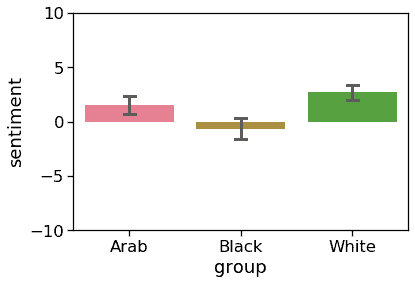
A significant difference can be observed between well-established popular word embeddings and the debiased ones when comparing similar texts where the name is changed to provide ethnical connotations. The figure above presents visible bias against people of color, while the usage of debiased word embeddings is presented below.

Conclusion
Not only should AI algorithms be fed with inclusive AI datasets where all races are equally represented to avoid discrimination, but also variables should be carefully chosen to avoid any potential bias against people of color.
Selecting less biased representations of our world (like word embeddings) should be incorporated as a standard in all solutions to serve fairness, not only in the NLP field. We should make sure that we create algorithms that serve everyone, not only a small part of society.
Verifying against exclusivity should be one of the most critical steps during the creation of machine learning software for any AI team to take. It is also crucial to focus on building awareness inside technology teams, which are creating these life-changing solutions.
Let’s make the future available for all of us.
References
- Angwin, J., et al. “Machine Bias.” ProPublica, 23 May 2016, accessed at www.propublica.org/article/machine-bias-risk-assessments-in-criminal-sentencing
- Bolukbasi, T., Chang, K.W., Zou, J.Y., Saligrama, V., and Kalai, A.T., 2016. Man is to computer programmer as woman is to homemaker? Debiasing word embeddings. In Advances in neural information processing systems (pp. 4349-4357).
- Buolamwini, J.A., 2017. Gender shades: intersectional phenotypic and demographic evaluation of face datasets and gender classifiers (Doctoral dissertation, Massachusetts Institute of Technology).
- Caliskan, A., Bryson, J., and Narayanan, A., 2017. Semantics derived automatically from language corpora contain human-like biases. Science, 356(6334), pp.183-186.
- Cuthbertson, Anthony. “Self-Driving Cars Are More Likely to Drive into Black People, Study Claims.” The Independent, Independent Digital News and Media, 6 Mar. 2019, www.independent.co.uk/life-style/gadgets-and-tech/news/self-driving-car-crash-racial-bias-black-people-study-a8810031.html.
- Flores, A.W., Bechtel, K., and Lowenkamp, C.T., 2016. False positives, false negatives, and false analyses: A rejoinder to machine bias: There’s software used across the country to predict future criminals. And it’s biased against blacks. Fed. Probation, 80, p.38.
- Ledford, H., 2019. Millions of black people affected by racial bias in health-care algorithms. Nature, 574(7780), pp.608-609.
- Jeffrey Pennington, Richard Socher, and Christopher D. Manning. 2014. GloVe: Global Vectors for Word Representation.
- Speer, R., 2017. ConceptNet Numberbatch 17.04: better, less-stereotyped word vectors. ConceptNet blog, Available at: https://blog.conceptnet.io/posts/2017/conceptnet-numberbatch-17-04-better-less-stereotyped-word-vectors/ Accessed 23 June 2020
- Speer, R., 2017. How to make a racist AI without really trying. ConceptNet blog, Available at: http://blog.conceptnet.io/posts/2017/how-to-make-a-racist-ai-without-really-trying/ Accessed 23 June 2020


