
After long development, Google released the first stable version of its Machine Learning library, TensorFlow.
The release is an important milestone in the development of a common Machine Learning toolkit. TensorFlow provides a set of primitives from which Machine Learning engineers and researchers can construct trainable models, as well as a framework to run these computations in an efficient way.

CPU vs. GPU
Deep neural networks training wouldn’t be possible without the advent of affordable, fast computational units. Training most kinds of Machine Learning models, including deep neural networks, consists of a lot of matrix operations. These operations are computationally heavy.
A modern GPU consists of thousands of processing cores with relatively low processing speed per core (as opposed to a CPU’s few cores with strong single-core performance). That means a GPU is highly robust, but only as long as we can distribute our computation.
Fortunately, certain operations, like said matrix multiplications, can be easily distributed and thus are perfectly fit for running on a GPU.
NVIDIA provides excellent GPU units thoroughly optimised for performing Machine Learning computations, as well as the CUDA framework, which is officially supported by TensorFlow. CUDA also provides a lot of helpful diagnostic utilities for debugging GPU programs (more on that later).
How different is developing applications with TensorFlow?
Classical programs execute instructions sequentially, line by line, with control flow instructions.
With TensorFlow, there are two phases:
-
Defining the computation graph as a series of math operations on matrices. We declaratively design the computational graph using a high-level language, such as Python:
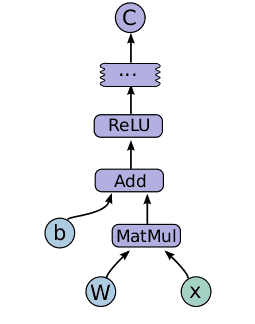
A computation graph for a simple neural network with one hidden layer. Source: http://www.iotenthu.com/2016/01/tensorflow-post-what-is-tensorflow-part-2-programming-model -
Running the graph on a CPU or a GPU, parameterising the graph with inputs (it’s called a Session). The Session object holds the state for an ongoing computation. TensorFlow then automatically translates our graph into assembly code for a target machine, whether it’s a CPU, GPU or even entirely different back-end.
A supercomputer at home
Most of the machines commonly used, especially laptops, don’t feature a GPU capable of optimizing neural networks training. This seriously limits the quality of model we can achieve.
A common method to increase the accuracy of a model is running multiple iterations of training on the same training set. A time necessary to train a model is directly proportional to the number of iterations of training.
Leveraging a strong GPU can bring the time of training down from weeks to hours. Yet the price of a dedicated GPU alone starts with $5,000… Ouch!

Solution: The cloud
Fortunately, the cloud providers like Amazon AWS and Google Cloud are doing their best to satisfy rising high-volume computation appetites.
In September of last year, Amazon AWS introduced EC2 P2, a cloud machine instance class featuring a NVIDIA Tesla K8 GPU suitable for Machine Learning applications. With EC2 P2, we can simply lease a machine starting at $0.90/hour (at the time of writing this article), and use it to train our models in an efficient way.
OK, enough talking… let’s get our hands dirty!
Setting up an EC2 P2 instance
Our objective will be to set up an EC2 P2 instance that we can use to run GPU computations with TensorFlow. We’re going to use the excellent Jupyter Notebook (formerly IPython Notebook) to experiment. We use this setup to provide machines for our deep learning workshops.
To use the AWS Cloud you must sign up and register your details and credit card if you haven’t already. This process is described here.
EC2 P2 instances are not normally enabled in the EC2 management console. They’re also not available in all AWS regions.
Because P2 is a relatively new service, to enable P2 instance creation, you need to request the service limit increase. To do that, open a ticket in the AWS Support:
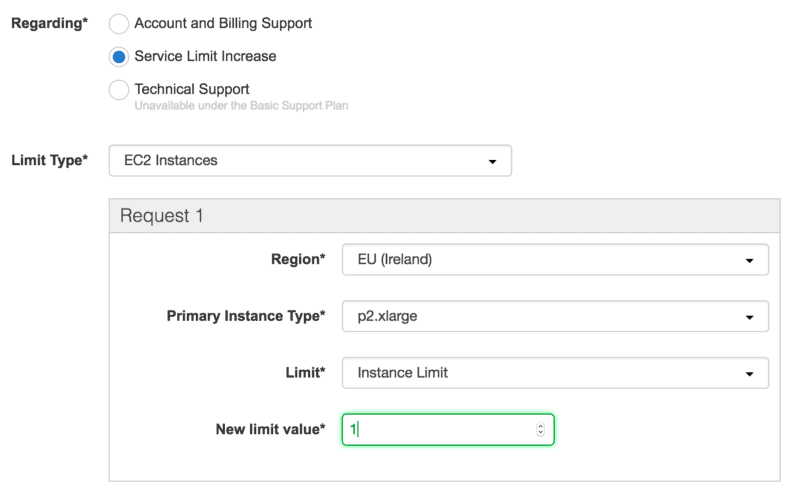
Within 24-48 hours, your P2 limit will be increased and you can set up a machine. I waited about 8 hours and was called by phone by an AWS representative:
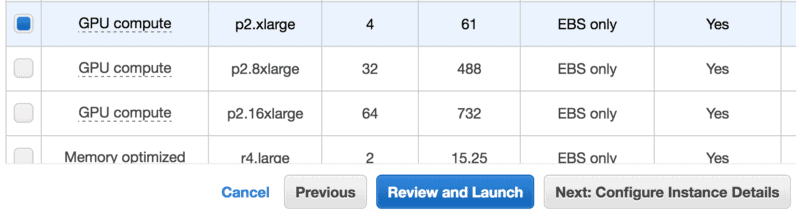
Press Next: Configure Instance Details. We need to refine some settings.
For this experimental setup, I recommend a Ubuntu 16.04 64-bit box. You’ll need to increase the default disk quota from 8 GB to 16 GB or more.
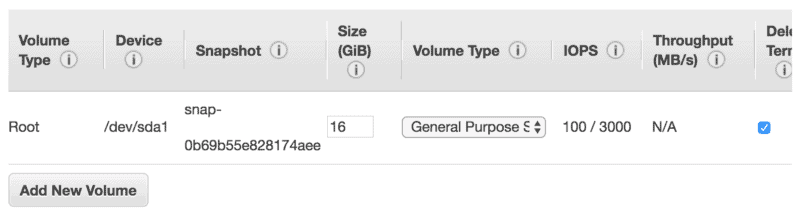
Next, make sure your group allows for inbound connections on port 8888. It will be required for the Jupyter Notebook to work.
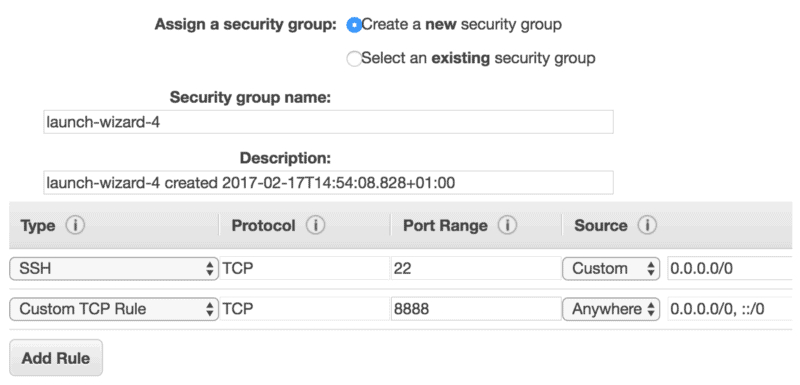
The last step will be to set up a key pair. You’ll need this in order to SSH into your newly-created machine.
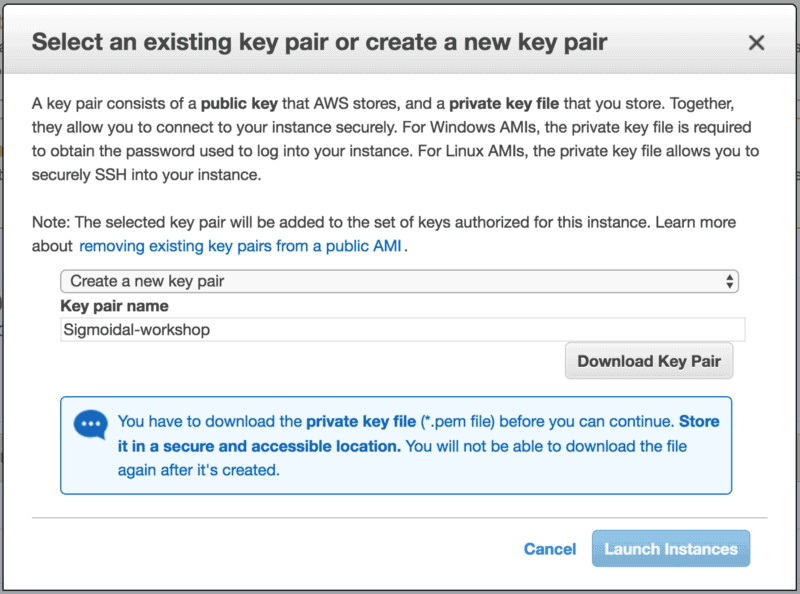
The machine is now running. Setting everything up is quite a pain, so I created a quick-and-dirty convenience script that you can execute via SSH on an existing machine that’s already running. It will install TensorFlow 1.0, Anaconda with Python 3.6, and host a Jupyter Notebook server on port 8888 that you can access from your local machine.
Note: before executing the script, you need to put libcudnn, NVIDIA’s deep networks library, in the /tmp directory of the machine. To obtain that library, register at the NVIDIA website first, then download the files.
The machine isn’t very secure. If you’re working with sensitive data, do make sure the cloud setup you’re using is more secure than the one shown here. Among other measures, you’ll want to make sure the machine you use is encrypted.
To obtain your machine’s IP address, open up the EC2 console:
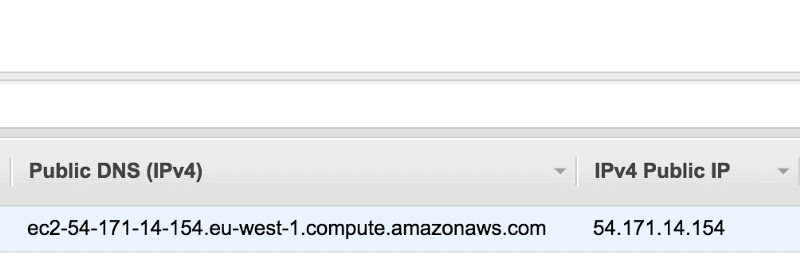
Now SSH into the machine using the .pem key file, and run the script.
The last step is opening http://[your-machine-ip]:8888 in your browser… and voilà!
A Jupyter Notebook, ready for our deep learning journey 🙂 Default password: sigmoidal
Training a simple deep network
Let’s train a neural network. We’re going to build a variant of a Convolutional Neural Network (CNN). A CNN is a kind of a deep network particularly fit, among other things, for the image classification task: deciding which class an image belongs to from among a predefined set of classes.
Our network is a simplified version of the ground-breaking AlexNet. In 2012, AlexNet set the new quality standard for performing image classification by a computer.
I’ve chosen the popular CIFAR-10 dataset, which contains images of everyday items and animals classified with 10 labels. Our objective is to build a system that precisely distinguishes between these classes.
I’ve prepared a Jupyter notebook with a deep network to play with. To work with it, just put it in the ~/notebooks directory of your machine and open it in Jupyter. Download it here.
This will download the data and run a classification task on the sample dataset. Because of GPU acceleration, we can train the machine with more iterations. With the default settings I’ve provided (6,000 iterations, 256 batch size) the training takes about two minutes.
We’re getting about 67% accuracy on the test set. It’s not bad for a network this simple, but we can do much better. Currently, the best-known result for this dataset in the academic world is 96%. Even without implementing more sophisticated methods, increasing the number of hidden nodes and training iterations should give us better results. Try it yourself!
Note that we achieve much better results on the subsequent training mini-batches as compared to the test set. This is due to overfitting to the training data. There are multiple ways to handle this, but it’s beyond the scope of this introductory post.

Is it really running on a GPU?
TensorFlow applications run on a GPU by default if one is available. If your network training takes too long, perhaps it’s worth making sure the GPU is being utilized.
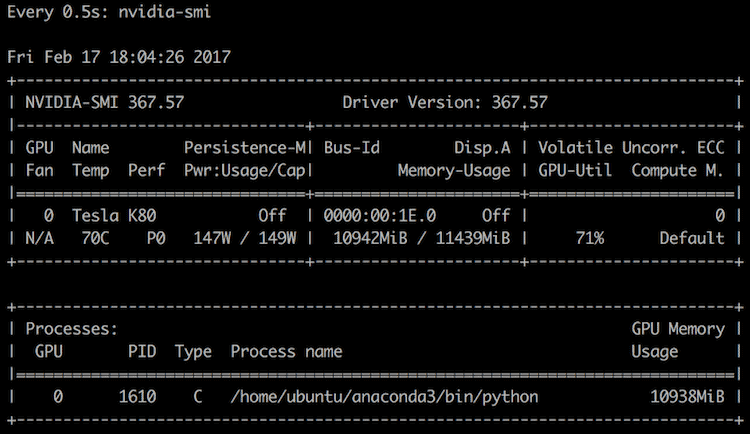
To see that utilization in real time, SSH into the machine, and type:
$ watch -n 0.5 nvidia-smi
You should see something similar to this, updated once every half second:
Don’t forget to stop the machine and wash your hands after you finish!
It’s quite costly and not much fun to pay $0.90/hour for nothing. If you stop the machine, you’ll still be charged a little for instance disk usage: you’ll retain your notebooks and your data if you decide to use this instance again. If, however, you’re finished, terminate the machine instance to avoid extra cost. It will later disappear from the list, and you’ll have to set it up from scratch.
About me
I’m open to any questions you might have about TensorFlow and Machine Learning, and I’m always willing to help, just ping me at mariusz@sigmoidal.io
I’m a founder of Sigmoidal, a boutique consultancy where we tackle Machine Learning and AI problems and advise our customers on the right use of AI for the good of their businesses, and for the world in general.


