Getting started with AI? Perhaps you’ve already got your feet wet in the world of Machine Learning, but still looking to expand your knowledge and cover the subjects you’ve heard of but didn’t quite have time to cover?
This Machine Learning Glossary aims to briefly introduce the most important Machine Learning terms, both for the commercially and technically interested. It’s not by any means exhaustive, but a good, light read prep before a meeting with an AI director or vendor, or a quick revisit before a job interview! Also, if you’re interested in similar terms related to Big Data, I’d encourage you to visit a similar blog post on our partner company, DevsData LLC.

Overview
- NLP: Natural Language Processing
- Dataset
- Computer Vision
- Supervised Learning
- Unsupervised Learning
- Reinforcement Learning
- Neural Networks
- Overfitting
1. NLP: Natural Language Processing
Natural Language Processing (NLP) is a common notion for a variety of machine learning methods that make it possible for the computer to understand and perform operations using human (i.e. natural) language as it is spoken or written.
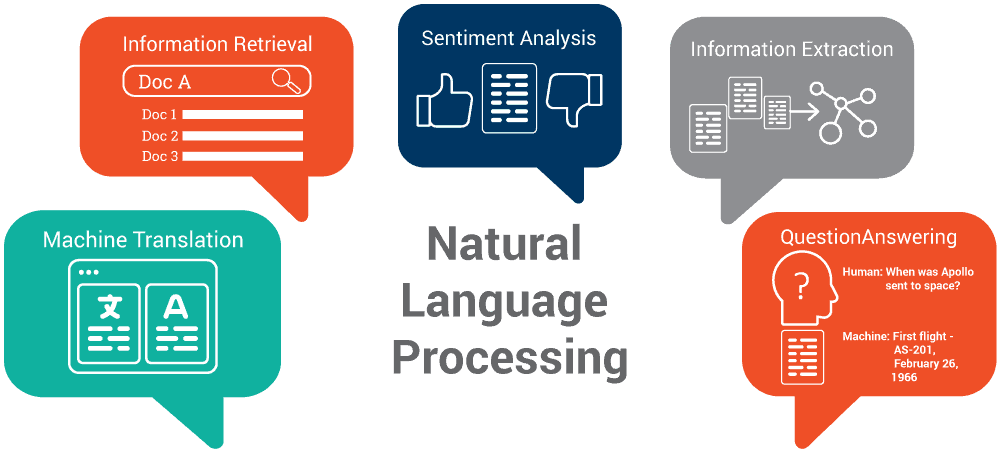
The most important use cases of Natural Language Processing are:
- Text Classification and Ranking
The goal of this task is to predict a class (label) of a document, or rank documents within in a list based on their relevance. It could be used in spam filtering (predicting whether an e-mail is spam or not) or content classification (selecting articles from the web about what is happening to your competitors).
- Sentiment Analysis
Sentiment analysis aims to determine the attitude or emotional reaction of a person with respect to some topic- e.g.,positive or negative attitude, anger, sarcasm. It is broadly used in customer satisfaction studies (e.g. analyzing product reviews).
- Document Summarization
Document Summarization is a set of methods for creating short, meaningful descriptions of long texts (i.e. documents, research papers).
Interested in Natural Language Processing? Read our in-depth article on Natural Language Processing in Artificial Intelligence
- Named Entity Recognition (NER)
Named Entity Extraction algorithms process a stream of unstructured text and recognize predefined categories of objects (entities) in it, such as a person, company name, date, price, title etc. It enables faster text analysis by transforming unstructured information into a structured, table-like (or JSON) form.
- Speech Recognition
Speech Recognition techniques are used for determining a textual representation of an audio signal of people speaking. You have probably heard of Siri, right? This is a good example of how Speech Recognition is used.
- Natural Language Understanding and Generation
Natural Language Understanding is used for transforming a human-generated text into more formal representations interpretable by a computer, and conversely: Natural Language Generation techniques support transformation of a formal logical representation into a human-like generated text. Nowadays, NLG and NLU are mostly used in chatbots and automated report generation.
Conceptually, it’s the opposite of Named Entity Recognition.
- Machine Translation
Machine Translation is the task of automatically translating text or speech from one human language into another.
2. Dataset
Data is an essential part of machine learning. If you would like to build any machine learning system you need to either get the data (e.g. from some public resource) or collect it on your own. All the data that is used for either building or testing the ML model is called a dataset. Basically, data scientists divide their datasets into three separate groups:
- Training data
Training data is used to train a model. It means that ML model sees that data and learns to detect patterns or determine which features are most important during prediction. - Validation data
Validation data is used for tuning model parameters and comparing different models in order to determine the best ones. The validation data should be different from the training data, and should not be used in the training phase. Otherwise, the model would overfit, and poorly generalize to the new (production) data. - Test data
It may seem tedious, but there is always a third, final test set (also often called a hold-out). It is used once the final model is chosen to simulate the model’s behaviour on a completely unseen data, i.e. data points that weren’t used in building models or even in deciding which model to choose.

3. Computer Vision
Computer Vision (CV) is a field of Artificial Intelligence concerned with providing tools for analysis and high-level understanding of image and video data. The most common problems in CV include:
- Image classification
Image classification is a CV task of teaching a model to recognize what is on a given image. For example, one could train a model to distinguish between various objects in the public space (that could be used with self-driving cars).
- Object detection
Object detection is a CV task of teaching the model to detect an instance of an object from a set of predefined categories by providing a bounding box around each instance of a given class. For example, one could use object detection to build a face recognition system. The model would then be able to draw a bounding box around every face it detects on the picture. (Btw. the image classification system would be only able to tell whether there is a face on the picture or not, and not to detect where is it, like object detection system could do).

- Image segmentation
Image segmentation is a CV task where one trains a model to annotate each pixel with a class from a predefined set to which a given pixel most probably belongs.
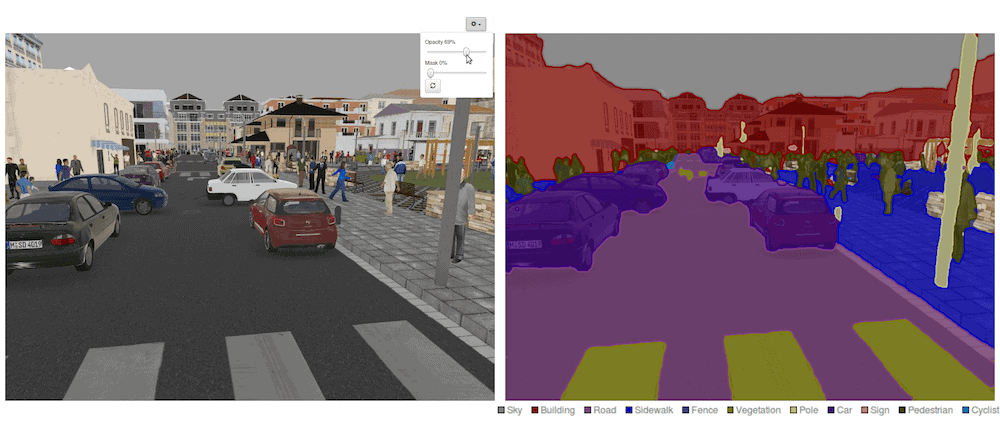
- Saliency detection
Saliency detection is a CV task of training a model to be able to provide a region which would most likely attract the attention of a viewer. This could be used to determine ad placement in videos.
Need more details on AI for Computer Vision? Read our article.
4. Supervised learning
Supervised learning is a family of machine learning models that teach themselves by example. This means that data for a supervised ML task needs to be labeled (assigned the right, ground-truth class). For instance, if we would like to build a machine learning model for recognizing if a given text is about marketing, we need to provide the model with a set of labeled examples (text + information if it is about marketing or not). Given a new, unseen example, the model predicts its target, e.g. for the stated example, a label (eg. 1 if a text is about marketing and 0 otherwise).
5. Unsupervised learning
Contrary to Supervised Learning, Unsupervised Learning models teach themselves by observation. The data provided to that kind of algorithms is unlabeled (there is no ground truth value given to the algorithm). Unsupervised learning models are able to find the structure or relationships between different inputs. The most important kind of unsupervised learning techniques is “clustering”. In clustering, given the data, the model creates different clusters of inputs (where “similar” inputs are in the same clusters) and is able to put any new, previously unseen input in the appropriate cluster.

6. Reinforcement learning
Reinforcement Learning differs in its approach from the approaches we’ve described earlier. In RL the algorithm plays a “game”, in which it aims to maximize the reward. The algorithm tries different approaches “moves” using trial-and-error and sees which one boost the most profit.
The most commonly known use cases of RL are teaching a computer to solve a Rubik’s Cube or play chess, but there is more to Reinforcement Learning than just games. Recently, there is an increasing number of RL solutions in Real Time Bidding, where the model is responsible for bidding a spot for an ad and its reward is the client’s conversion rate.
Eager to catch up with the AI revolution in programmatic advertising and RTB
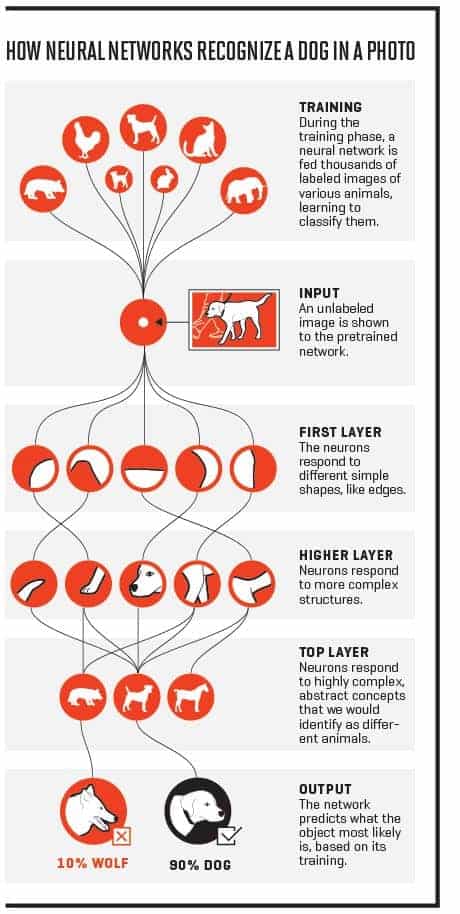
7. Neural Networks
Neural Networks is a very wide family of machine learning models. The main idea behind them is to mimic the behaviour of a human brain when processing data. Just like the networks connecting real neurons in the human brain, artificial neural networks are composed of layers. Each layer is a set of neurons, all of which are responsible for detecting different things. A neural network processes data sequentially, which means that only the first layer is directly connected to the input. All subsequent layers detect features based on the output of a previous layer, which enables the model to learn more and more complex patterns in data as the number of layers increases. When a number of layers increases rapidly, the model is often called a Deep Learning model. It is difficult to determine a specific number of layers above which a network is considered deep, 10 years ago it used to be 3 and now is around 20.
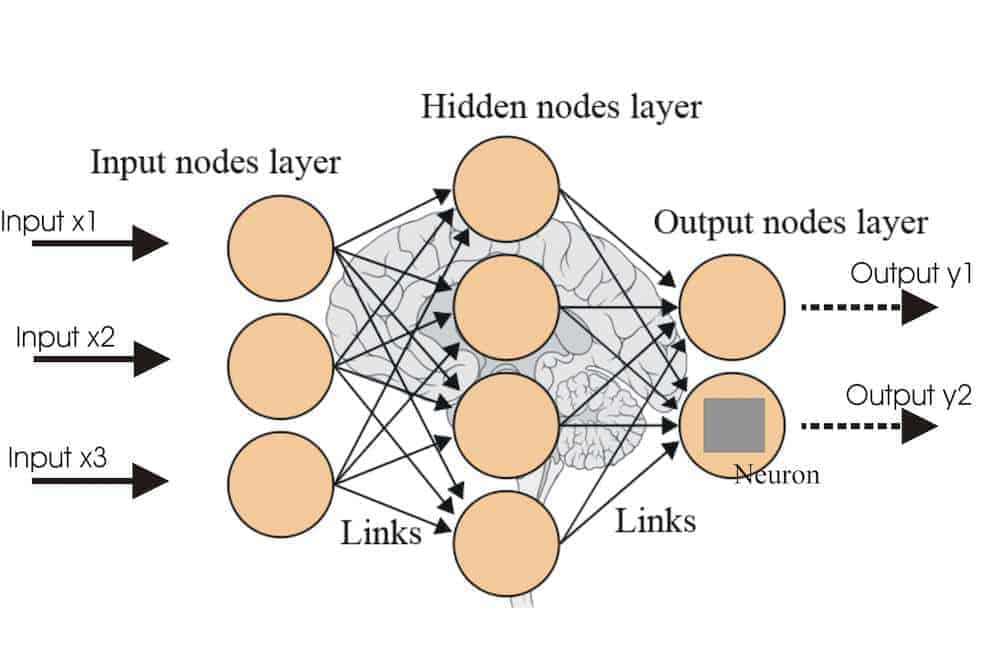
There are many different variations of Neural Networks. Most commonly used are:
- Convolutional Neural Networks: These were a huge breakthrough in Computer Vision tasks (but recently, they also proved very useful in NLP problems).
- Recurrent Neural Networks: Designed to process data with sequential nature such as texts or stock prices. They are relatively old, but as the computing power of modern computers dramatically increased during the last 20 years, they became feasible to train and use in a reasonable time.
- Fully Connected Neural Networks: The simplest model used on static/tabular data.
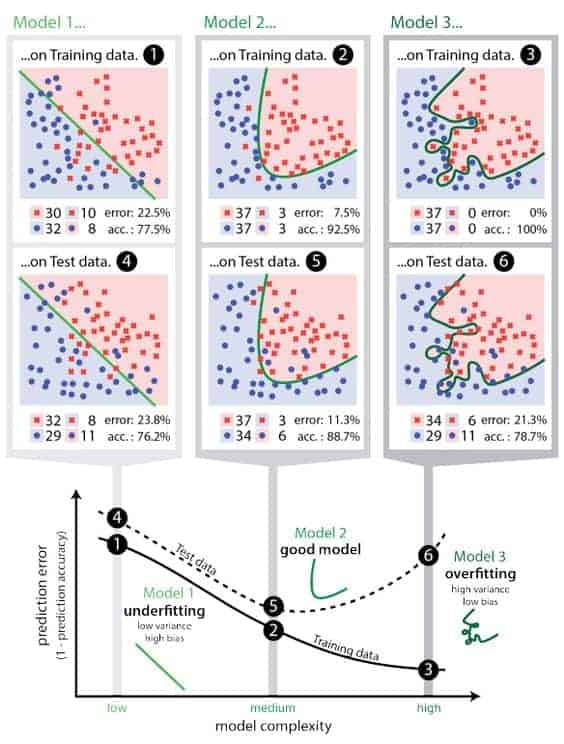
8. Overfitting
It’s a negative effect when the model builds an assumption (bias) from an insufficient amount of data. A fairly common, and very important problem. Let’s say that you’ve visited a bakery a couple of times, and not once was there your favourite cupcake left! You’d likely get disappointed with the bakery, even though a thousand of other customers might find the stock satisfying. If you were a machine learning model, it’d be fair to say you’ve overfit against a small number of examples: developed a biased model, a representation in your head, that isn’t accurate compared to the facts.
When overfitting happens, it usually means that the model is treating random noise in the data as a significant signal and adjusts to it, which is why it deteriorates on a new data (as the noise there is different.) This is generally the case in very complex models like Neural Networks or Gradient Boosting.
Imagine building a model to detect articles mentioning a particular sport discipline practiced during olympics. Since your training set is biased toward articles about the olympics, the model may learn features like presence of a word “olympics” and fail to detect correct articles that do not contain that word.