
Since 2012 when AlexNet appeared and broke almost all the records in image classification contests, the landscape of the Computer Vision (CV) community has completely changed. There has been an exponential growth in the number of Computer Vision solutions based on convolutional neural networks (CNNs) in the past five years, and this trend seems to be continuing.
Because it’s so easy to reuse professionally pretrained networks like Microsoft ResNet or Google Inception, implementing and understanding CNNs for tasks like image classification and regression has gotten exponentially easier, even for a beginner Deep Learning researcher. But deep learning can do a lot more than this.
In this post, we will concentrate on some specific, sophisticated visual tasks that deep learning can help accomplish. These are tasks where we are not only interested in image recognition, but also want to automatically infer the actual position of detected objects from a provided image: object detection, image segmentation and object instance segmentation (with masking).

Object detection
The main aim of object detection task is to detect the object (or a set of objects) from a predefined set of classes as well as detect the minimal sufficient bounding box around each object instance.
This problem is usually tackled by:
- Producing the set of candidate region proposals
- Classifying each of them using a neural network designed and trained specifically for this purpose.
The most difficult part of this process is to effectively find reasonable proposals.
In the beginning, classic and relatively sophisticated CV techniques were used in order to find appropriate candidates. This process slowly evolved into an end-to-end deep learning solution called Faster R-CNN, where CNNs are used for both finding proposals (so-called Region Proposal Networks, RPNs), and classification. It’s worth mentioning that these two networks (RPNs and networks used for classification) share a huge part of their parameters, which speeds up the training process and increases the accuracy of both candidate region selection as well as its final prediction and evaluation.
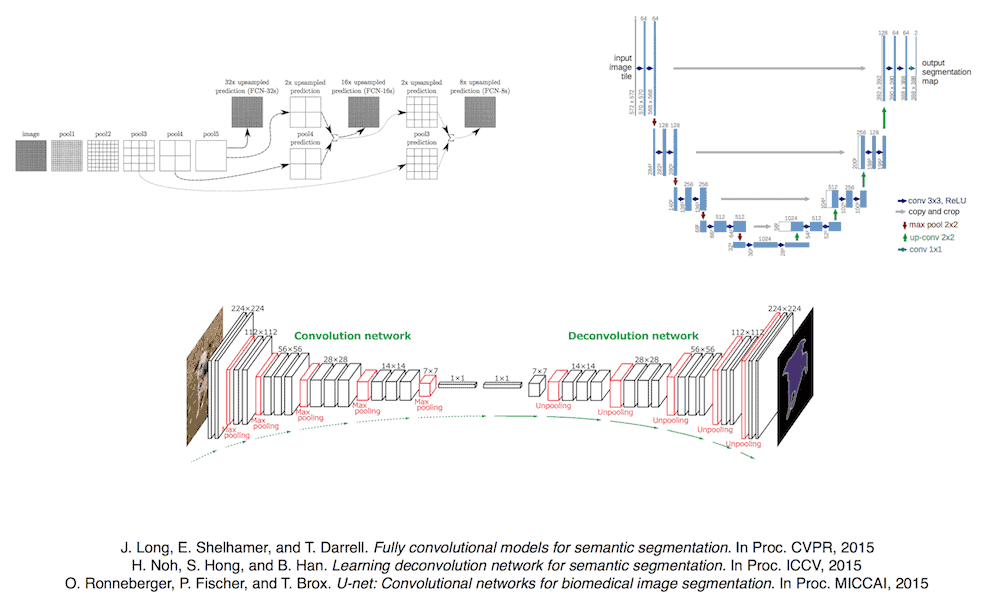
Image segmentation
In the most basic image segmentation definition, the algorithm performs a pixel-wise classification, which assigns one class to a pixel. It does this by using the predefined set of classes (or a probability distribution, which measures how a given pixel is probable to belong to the given class). Usually, when any other class is not assigned to the given pixel, an extra background class is added.
The main difficulty of this task is that most of existing CNN topologies tend to favor the increase of the semantic complexity over the actual spatial precision of deeper filters in a network. To deal with this challenge, we use pooling/downsampling layers which decrease the resolution of feature maps. Although in case of regression and classification such approach is reasonable (mainly because the general features of an image should be properly detected), if the network is to produce the full-resolution feature map, these downsampling techniques may result in poor performance.
Deconvolution
To avoid the performance loss caused by downsampling, we use an intelligent upsampling technique called deconvolution. Using this method, which works exactly like upsampling convolution, we make it possible to increase the resolution of a feature map in CNN data flow. Most of the time, these upsampled feature maps are combined with precedent feature maps in the network- or even the original input image- in order to obtain more accurate predictions. The most popular architectures which work in this manner are: U-Nets and Fully Convolutional Neural Networks (FCNs).

Object instance segmentation with masking
This task can be considered as a combination of the previous two tasks. The main purpose of object instance segmentation with masking is to find a binary mask for every instance of objects from a predefined set of classes.
The current state-of-the-art solution for this problem, called Mask R-CNN, is a brilliant combination of the techniques used for both object detection and image segmentation. Whereas in Faster R-CNN the convolutional shared layers model part is a base for both region proposal and classification outputs, in Mask R-CNN, an additional segmentation branch is added.
Thanks to this branch, each instance is provided with the bounding boxes and a full object mask. Because of the fact that training of the additional image segmentation part also influences the shared convolutional base, it positively affects other output branches of the model. Thanks to this phenomenon, the model, which has been designed for an object instance segmentation,is able to achieve a new record on a highly recognized MS COCO 2016 dataset for an object detection.
Summary
Image recognition and regression are only the tip of the iceberg when it comes to successful deep learning applications. Thanks to increasing algorithmic and computational progress, more and more real-life applications of image recognition and regression may experience a huge boost in the coming years. At the same time, as more and more solutions are designed in an end-to-end manner, the need for Deep Learning expertise is rapidly decreasing. Needless to say, the industry faces some interesting changes as our technology continues to improve.


