
Design specs. Write software. Test it, fix bugs, post to production.
Agile development is omnipresent in the software development world. However, the Machine Learning development is more like a creative research process. There are certain similarities though, which I’d like to shortly outline here.
For those of you that never worked on building an end-to-end Machine Learning solution, I’d like to shed light on this process.
1. Specify your expectations to determine ROI
In Machine Learning our system has a precisely-defined task, like recognizing text on an image. To determine business plausibility, we need to understand: how good our algorithm needs to be to bring us a return on investment?
Let’s imagine we have a regular, rule-based algorithm (without Machine Learning), that is 70% effective in automating a human task, like insurance underwriting, i.e. it can automate away the task in 7 in 10 cases. Will an increase to 80% yield an improvement good enough to justify the investment?
Action item: Determine the threshold when the investment returns.
2. Determine the “state of the art” solution
Before tackling any software development project, we do research on existing solutions, libraries, algorithms etc.
When working on a Machine Learning project, we do the same, but along with libraries, it’s important to review the scientific literature.
State of the art: the best solution to a definite problem known in the academic world. For example, currently state of the art solution to the MNIST digits classification problem is 0.21% error.
Action item: Research the current state of the art for a problem similar to yours. You will probably not do better. Is the solution satisfying?

3. Collect high-quality training data (but not too much)
The biggest threat to any Machine Learning solution is not having enough clear, meaningful data.
🦃 Did you know that Docker can run your GPU app? Learn how to dockerize a GPU-powered Keras deep neural network to run in production and scale up!
Too noisy data will lead to building an algorithm giving unsatisfying results, i.e., learning from the noise. Too little data will make it not general enough (a phenomenon known as underfitting).
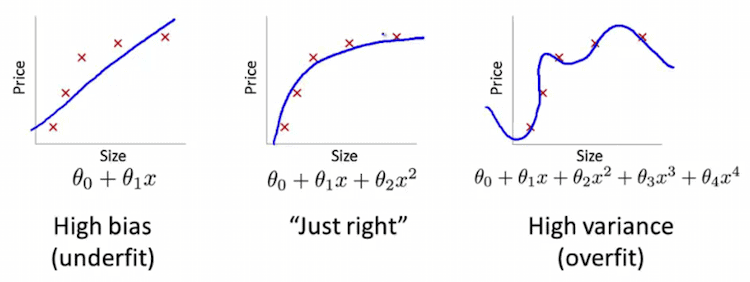
Yet getting more data is often an expensive (time or money) process and is not usually justified at the very beginning of the process. A decision to collect more data must be informed.
Action item: Determine how much data you can gather without spending too much. Determine how much it would take (time and money) in order to get more data.
4. Pre-process and augment data
Let’s consider the problem of customer segmentation, where we try to split a customer base into segments. We may want to do this to target them with different types of marketing message or branding.

What information about a customer do we need to determine his fit for a particular profile? Surely demographics or purchase history would be useful.
If the data isn’t relevant (like the first or last name), though, it can confuse the algorithm.
But can (and should) we collect more features? We might want to augment our customer profile with social media information or infer e.g. their income group based on other features. If we’re good enough in this, we can even use that to win a US election.
Action items: Determine, which features have proven relevant when working on this problem. What expert knowledge do you already have? How can you augment your dataset?
5. Design some number of experiments
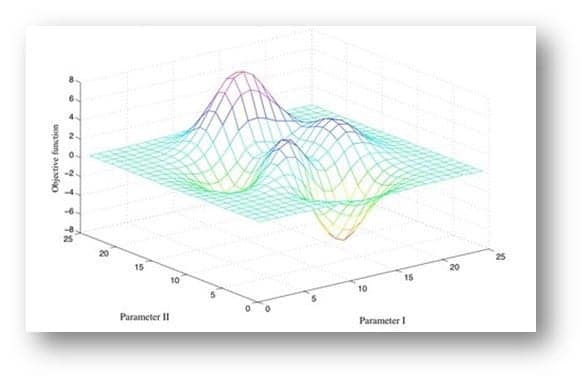
Now that we have our dataset ready, we need to design experiments and evaluate them.
Action items
- Define 10-20 experiments you’d like to go with and try to train them for a limited time.
- Determine a couple of them that are significantly better than the others. Run a grid search (or a variation) to determine a winner combination of algorithm and hyperparameters.
6. Refine your final algorithm(s)
Now that you have your winner algorithm and parameter set, try to make it even better.
Action items
- Is your model overfitting to the training set? If so, you can get more data to enhance the model quality.
- Are there any more parameters you can fine-tune?
- Are you satisfied with the result? Try deploying your model in a production environment. How does it handle a real-world challenge?


