Attention mechanisms revolutionized machine learning in applications ranging from NLP through computer vision to reinforcement learning. Attention is the key innovation behind the recent success of Transformer-based language models such as BERT.1 In this blog post, I will look at a first instance of attention that sparked the revolution: additive attention (also known as Bahdanau attention) proposed by Bahdanau et al.2
The idea of attention is quite simple: it boils down to weighted averaging. Let us consider machine translation as an example. When generating a translation of a source text, we first pass the source text through an encoder (an LSTM or an equivalent model) to obtain a sequence of encoder hidden states  . Then, at each step of generating a translation (decoding), we selectively attend to these encoder hidden states, that is, we construct a context vector
. Then, at each step of generating a translation (decoding), we selectively attend to these encoder hidden states, that is, we construct a context vector  that is a weighted average of encoder hidden states:
that is a weighted average of encoder hidden states:
![\[\mathbf{c}_i = \sum\limits_j a_{ij}\mathbf{s}_j\]](/assets/b4ebd58246-69f9124ba310cbe04358c08d_69f91227c639525e78a50e49_quicklatex.svg)
We choose the weights  based both on encoder hidden states and decoder hidden states
based both on encoder hidden states and decoder hidden states  and normalize them so that they encode a categorical probability distribution
and normalize them so that they encode a categorical probability distribution  .
.
![\[\mathbf{a}_i = \text{softmax}(f_{att}(\mathbf{h}_i, \mathbf{s}_j))\]](/assets/b30862af1d-69f9124ba310cbe04358c0ba_69f9123611886df9ca7caaea_quicklatex.svg)
Intuitively, this corresponds to assigning each word of a source sentence (encoded as  ) a weight that tells how much the word encoded by is relevant for generating subsequent
) a weight that tells how much the word encoded by is relevant for generating subsequent  th word (based on
th word (based on  ) of a translation. The weighting function
) of a translation. The weighting function  (also known as alignment function or score function) is responsible for this credit assignment.
(also known as alignment function or score function) is responsible for this credit assignment.
There are many possible implementations of  , including multiplicative (Luong) attention or key-value attention. In this blog post, I focus on the historically first and arguably the simplest one: additive attention.
, including multiplicative (Luong) attention or key-value attention. In this blog post, I focus on the historically first and arguably the simplest one: additive attention.
Additive attention uses a single-layer feedforward neural network with hyperbolic tangent nonlinearity to compute the weights :
![\[f_{att}(\mathbf{h}_i, \mathbf{s}_j) = \mathbf{v}_a{}^\top \text{tanh}(\mathbf{W}_1 \mathbf{h}_i + \mathbf{W}_2 \mathbf{s}_j)\]](/assets/9f8ed755ab-69f9124ba310cbe04358c0ab_69f9123dff60b9894cbe9ec3_quicklatex.svg)
where  and
and  are matrices corresponding to the linear layer and
are matrices corresponding to the linear layer and  is a scaling factor.
is a scaling factor.
PyTorch Implementation of Additive Attention
class AdditiveAttention(torch.nn.Module):
def __init__(self, encoder_dim=100, decoder_dim=50):
super().__init__()
self.encoder_dim = encoder_dim
self.decoder_dim = decoder_dim
self.v = torch.nn.Parameter(torch.rand(self.decoder_dim))
self.W_1 = torch.nn.Linear(self.decoder_dim, self.decoder_dim)
self.W_2 = torch.nn.Linear(self.encoder_dim, self.decoder_dim)
def forward(self,
query, # [decoder_dim]
values # [seq_length, encoder_dim]
):
weights = self._get_weights(query, values) # [seq_length]
weights = torch.nn.functional.softmax(weights, dim=0)
return weights @ values # [encoder_dim]
def _get_weights(self,
query, # [decoder_dim]
values # [seq_length, encoder_dim]
):
query = query.repeat(values.size(0), 1) # [seq_length, decoder_dim]
weights = self.W_1(query) + self.W_2(values) # [seq_length, decoder_dim]
return torch.tanh(weights) @ self.v # [seq_length]Here _get_weights corresponds to , query is a decoder hidden state and values is a matrix of encoder hidden states  . To keep the illustration clean, I ignore the batch dimension.
. To keep the illustration clean, I ignore the batch dimension.
In practice, the attention mechanism handles queries at each time step of text generation.
Here context_vector corresponds to . h and c are LSTM’s hidden states, not crucial for our present purposes.
Finally, it is now trivial to access the attention weights and plot a nice heatmap.
attention = AdditiveAttention(encoder_dim=100, decoder_dim=50)
encoder_hidden_states = torch.rand(10, 100)
decoder_hidden_states = torch.rand(13, 50)
weights = torch.FloatTensor(13, 10)
for step in range(decoder_hidden_states.size(0)):
context_vector = attention(decoder_hidden_states[step], encoder_hidden_states)
weights[step] = attention._get_weights(decoder_hidden_states[step], encoder_hidden_states)
seaborn.heatmap(weights.detach().numpy())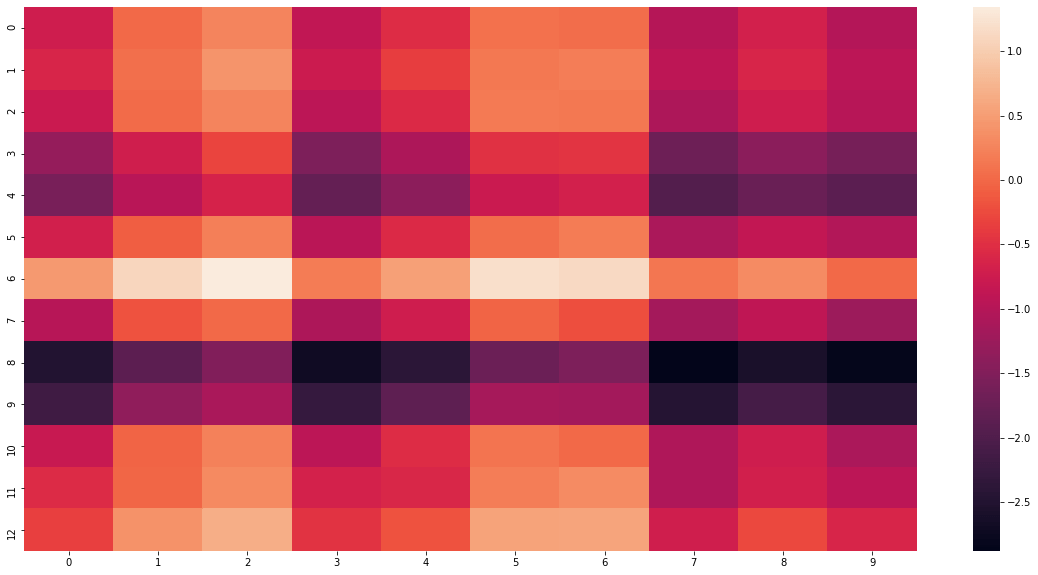
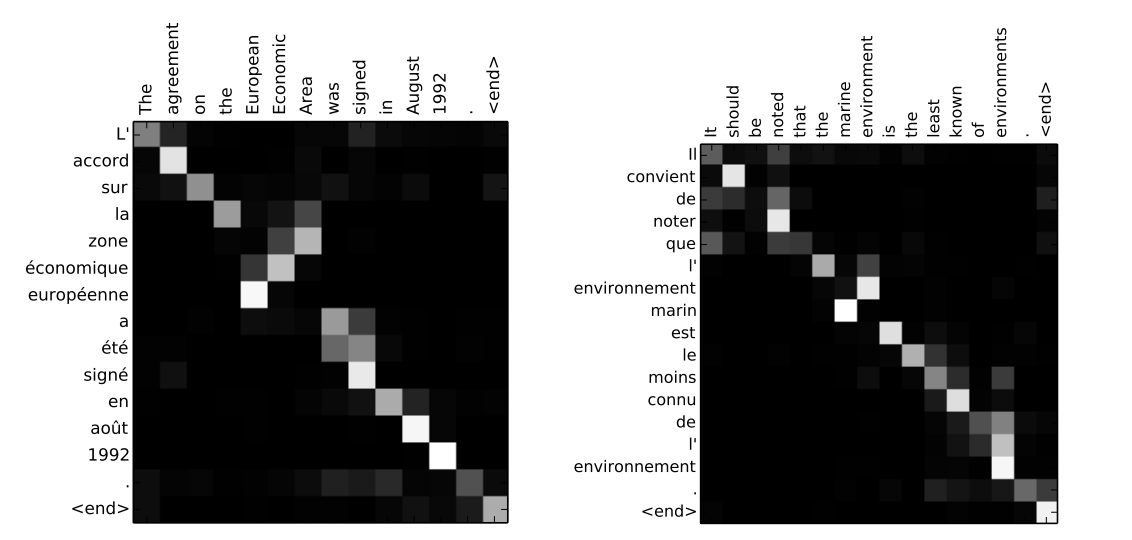
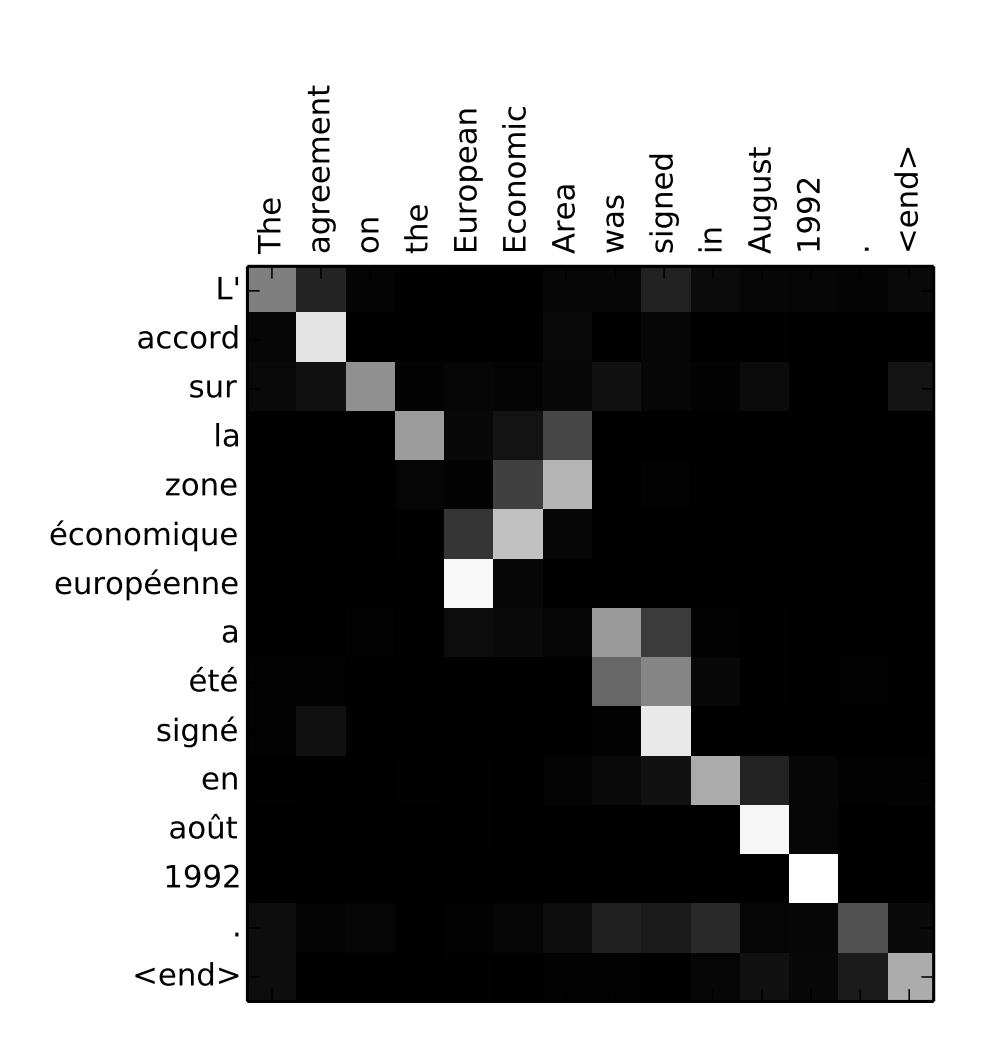
Here each cell corresponds to a particular attention weight . For a trained model and meaningful inputs, we could observe patterns there, such as those reported by Bahdanau et al.: the model learning the order of compound nouns (nouns paired with adjectives) in English and French. Let me end with this illustration of the capabilities of additive attention.
- Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova (2019). BERT: Pre-training
of deep bidirectional transformers for language understanding. Annual Conference of the North
American Chapter of the Association for Computational Linguistics. ↩︎ - Dzmitry Bahdanau, Kyunghyun Cho and Yoshua Bengio (2015). Neural Machine Translation by Jointly Learning to Align and
Translate. International Conference on Learning Representations. ↩︎


