
Ever wondered how Google knows what you mean even though you make spelling mistakes in each word of your query? In this short post, we would like to discuss a very simple but efficient method of fuzzy matching. It allows you to find the non-exact matches to your target phrase; not synonyms but rather phrases or terms that are constructed in a slightly different way than expected. For example, it would not find the word interesting for the query fascinating, but it would find United States of America for United States. For more information about the idea behind fuzzy matching, please refer to this article.
Fuzzy Matching: Introduction
Exact searching is not an option. Although sometimes we can be lucky enough to have it in our database, more often we aren’t. We have to use fuzzy matching! So suppose that we have the following database of terms or phrases as in the figure below.
We need a way to somehow compare records from our database with a given query.
![\[d(\textbf{some text}, \textbf{query text}) = \textbf{matching score}\]](/assets/3e58a3614f-69f912732d72d065fbd510a4_69f91251c42fd1b8d9d829e4_quicklatex.svg)
There are quite a lot of techniques that are useful for measuring the distance between strings. One of the most popular and for many applications the best one is a function called Levenshtein distance. Its score is a natural number beginning from 0. Its interpretation is a number of edits needed to transform one string into another. By edit we mean a set of operations, e.g. insertion or substitution. We don’t want to spend much time on Levenshtein itself here. There are a lot of sources that explain it. One of them is this article.
Having decided on the function comparing strings, we still need to figure out when to use it. Theoretically, we could use it for every term in our database, but it would be very time-consuming. If the Levenshtein computation is done N times, and N is quite big, it can be too big from a practical point of view. Let’s introduce a simple idea and check if it works. Select a small number of phrases that potentially are good candidates for a match and on this small subset of candidates compute Levenshtein distance. So the procedure would consist of two steps:
- Select a small number of candidates, let’s say n of them, where

- Compute Levenshtein distance between each candidate and a query string
The second step is obvious. After having done it, we can return the string whose Levenshtein distance turned out to be the smallest one. The first step requires an explanation. In order to find candidates, we begin with vectorizing our phrases. We count the number of specific characters and then normalize it. The sum of all components is equal to 1. The query phrase is vectorized the same way.
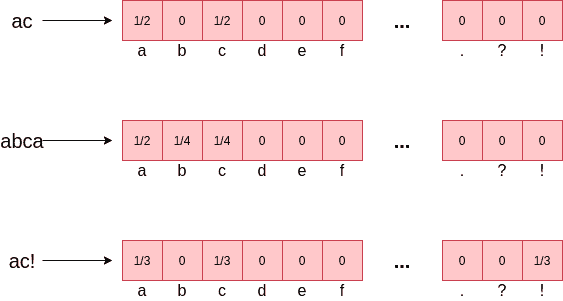
When comparing two vectors with each other euclidean distance is a quite popular choice. Let’s pick it. We’ll select candidates based on the distance between query string vector representation and vector representations from our database. As a quick recap, euclidean distance (to be more precise taken to the power of 2) is computed as below:
‖x − y‖² = Σi=1N (xi − yi)²
Let’s stop here for the moment and think if it makes sense for our application. We’ll look at a couple of cases just to have a better feeling.
- query string is equal to
ac, then distances are 0, and
and  . Winning phrase:
. Winning phrase: ac; - query string is equal to
c, the distances are ,
,  ,
,  . Winning phrase:
. Winning phrase: ac - query string is equal to
abca!!!!, the distances are ,
,  ,
,  . Winning phrase:
. Winning phrase: ac!
What can we say about the above results? The first two of them would be chosen if we used Levenshtein distance directly, which is good. But the third case should pick abca according to Levenshtein distance. It turns out that the bigger the string (in either the database or the query), the less impact each character has, and this can affect the final result. Let’s add two comments.
- In the above examples, we haven’t considered the case of a palindrome. A phrase
acandcaare presumably entirely different phrases, but with our approximation, its distance is equal to 0. The problem is more general. Simply speaking, we ignore the order of characters. - To have more precise approximation and also to mediate the effect of ignoring the order we should not only take single characters into account but also n-grams (like 2, 3, or 4) when vectorizing.
The vectorization that works is only slightly more involved, but it pays off.
- Use the “bag of words” vectorizer for database strings and the query string and normalize the resulting vectors so that the sum of their components is equal to 1.
- Compute the norms for all the vectors.
- Compute dot product between all vectors and the query vector and divide it by the multiplication of its norms.
The last two steps are just cosine similarity, but we described this way so that we can have a mechanical description of calculations that must be done. Besides, we can compute norms just once (for database strings) and then use them without the need for recalculation every time a new query comes.
The code will speak by itself and if anything has been unclear so far you the code will help.
Code
import numpy as np
import scipy.sparse as sparse
from sklearn.feature_extraction.text import CountVectorizer
strings = ['ac', 'abca', 'ac!']
query = 'abca!!!!'
def create_sparce_from_diagonal(diag: np.ndarray) -> sparse.csr_matrix:
"""Creates sparse matrix with provided elements on the diagonal."""
n = len(diag)
return sparse.csr_matrix((diag, (list(range(n)), list(range(n)))), shape=(n, n))
def normalize_sparse_matrix(matrix: sparse.csr_matrix) -> sparse.csr_matrix:
"""Normalizes each row so that the sum of components is equal to one."""
sums_for_strings = matrix.sum(axis=1).A.flatten()
normalization_matrix = create_sparce_from_diagonal(1 / (sums_for_strings + 0.1))
return normalization_matrix.dot(matrix)
def compute_norms(matrix: sparse.csr_matrix) -> np.ndarray:
"""Computes norms for each row."""
return np.sqrt(matrix.multiply(matrix).sum(axis=1).A).flatten()
vectorizer = CountVectorizer(
ngram_range=(1, 4),
lowercase=True,
binary=False,
analyzer='char'
)
X = vectorizer.fit_transform(strings)
X = normalize_sparse_matrix(X) # step 1
norms = compute_norms(X) # step 2
query_vector = vectorizer.transform([query])
query_vector = normalize_sparse_matrix(query_vector)
query_norm = compute_norms(query_vector)
# step 3
similarities = X.dot(query_vector.T).A
similarities = similarities / (norms.reshape((-1, 1)) * query_norm.reshape((1, -1)))
best_string = strings[np.argmax(similarities.flatten())]
best_string

