
If you have a business with a heavy customer service demand, and you want to make your process more efficient, it’s time to think about introducing chatbots. In this blog post, we’ll cover some standard methods for implementing chatbots that can be used by any B2C business.
Introduction
Any business oriented towards creating a top of the line customer experience needs a competent and comprehensive customer service department. In the past, offering a reliable phone number with an informed customer service team was enough to satisfy customers with questions and problems. However, in today’s modern world, customers tend to expect a new level of ease and speed whenever they need to contact your company with a problem. This fix-it-now attitude causes a lot of frustration with infolines and talking to consultants who are either uninformed or detached from the customer’s problems and needs.
Because of these shifting expectations, companies are starting to introduce a chat option as a means of instant contact with their clients. The chat option allows more freedom, allowing your customer to start a conversation whenever and wherever they need to, for as long as they need to. Ideally, customers look for chats that are available 24/7 and provide information on every type of customer issue.
Telecom companies, in particular, are turning to this option to deal with the high level of customer inquiries that they receive on a daily basis. Our experience working directly with telecom companies on this issue has given our company a thorough understanding of how to make the process of using chatbots more efficient when dealing with high levels of chat volumes. This blog post outlines the process and discusses tips on understanding how to make the technology behind chatbots work for your customer service needs.
Automation and data preparation: Preprocessing and building your ontology
When creating a successful chatbot, your goal is to completely automate the process to minimize the need for human management as much as possible. To achieve this automation, there are two main options. The first option is to empower your consultants with answer suggestions provided by AI to facilitate customer service initiatives. This option still requires hiring and managing customer service teams. The second option is to completely replace all consultants with a chatbot, eliminating the need for customer service representatives altogether. We concentrate here on the second option, which is more demanding but provides a bigger payoff over time.
So we are set: our goal is to build a chatbot which would satisfactorily converse with customers of your telecom company.
In any task involving Machine Learning, the first step is to prepare data so that it can be correctly interpreted by the machine. In the case of creating a chatbot, the task consists of inputting thousands of existing interactions between customers and customer service representatives to teach the machine which words/phrases are sensitive to the industry. This process is called creating an ontology.
The next step in the process is called pre-processing. This step is needed to incorporate grammar into machine understanding and it allows us to identify any misspellings correctly within texts.
Pre-processing consists of tokenizing, stemming and lemmatizing the chats in order to render them readable to a bot. Most often this can be done by freely available NLTK tool that you can find online. The final effect of preprocessing is that you create accessible parse trees of the company chats, serving as a reference for the bot.
Chatbots
Once the ontology is created and the preprocessing is completed, it’s time to consider what kind of chatbot you would like to use. There are two main models for a chatbot:
- Retrieval-based model: this kind of chatbot uses a repository of predefined responses. The programmer chooses an appropriate response based on context following a given heuristic, which can be either something very simple or quite complex depending on the situation.)
- Generative model: A generative model chatbox doesn’t use any predefined repository. This kind of chatbot is more advanced, because it learns from scratch using a process called “Deep Learning.”
The pro for using a retrieval-based model is the fact that it won’t make grammatical mistakes, however, it will be rigid too, and thus not likely to appear „human”. Generative models, however, don’t guarantee either to appear „human”, however they can adapt better to surprising demands and questions from customers. Needless to say, a generative model is harder to perfect, and our current state of knowledge can get us only so far (the Turing test has not been passed yet!). For now, going with a generative model option means accepting that you won’t be able to build a perfect chatbot for every task.
However, in the case of a customer service chatbot for telecom companies. The industry is specific enough that creating a successful generative model option is feasible.
Generative models, however, don’t guarantee either to appear „human”, however they can adapt better to surprising demands and questions from customers.
In order to see which option works best for you, you should start by performing a statistical analysis of the typical demands on your customer service department. By filtering chats by the length of the conversation, you can easily determine whether your inquiries tend to be complicated or simple. If most of your customer interactions are short and to the point, they can be pretty easily automated. In longer conversations, a machine needs to keep track of what was being said in previous paragraphs. This is often surprisingly difficult and will more likely require a generative model chatbot.
Let’s get back to our case. Say you’ve performed a quick statistical analysis and it happened that around 65% of your chats are short (say 10 lines or less). You are now opting for a retrieval-based model, so let’s see what we can do.
Chatbots are cool and interactive, but there’s more to NLP. Extracting info from natural text can be a gold mine!
Deep learning
At this point, your data is prepared and you have chosen the right kind of chatbot for your needs. You will have a sufficient corpora of text on which your machine can learn, and you are ready to begin the process of teaching your bot. In the case of a retrieval model bot, the teaching process consists of taking in an input a context (a conversation with a client with all prior sentences) and outputting a potential answer based on what it read. Google Assistant uses a retrieval-based model (Smart Reply, Google). Which can help give you an idea of what it looks like.
In order to process the data, which in the case of a telecom company would consist of words, it is better to first transform the data into numbers, because this is how the machine will eventually need to process the data. There are a couple of ways to do this. One way is by turning words into vectors to construct a new vocabulary. For example, the word2vec (word2vec) system learns vocabulary from a training data (the existing chats) and then associates a vector with each word in the training data. Those vectors capture many linguistic properties, for example:
vector('Paris') - vector('France') + vector('Italy') = vector('Rome')To view some examples of how words get converted into vectors you can visit this word2vec archive. Another way to create a new vocabulary and turn your text corpus into vectors is by using TensorFlow and TensorFlow’s Example format. You can find a tutorial on how to use it here. Another tool for word representation is GloVe. All of these are convenient and relatively simple options for converting your text into vectors that your bot will be able to read and digest.
The next step is to actually ‘teach’ your chatbot how to answer specific questions. In a way, building a chatbot is similar to building a translator: giving answers to a given question is similar to translating from one language to another. Methods used for both tasks are also similar and require the “deep learning” process discussed earlier. The goal is to train a machine to answer correctly given particular context. In particular, it should be able to answer something correctly even if it exists in previously unseen contexts. To do this, we need to build a correct architecture. There are a plethora of choices on the type of architecture you want to build, and it will depend on your needs and preferences which one you want to go with.
TensorFlow comes with the seq2seq module (seq2seq tutorial) which consists of two recurrent neural networks (RNNs): an encoder that processes the input and the decoder that generates the output. This option has the following standard architecture (A, B, C are inputted to the encoder, ‘go’, W, X, Y, Z inputs to the decoder):
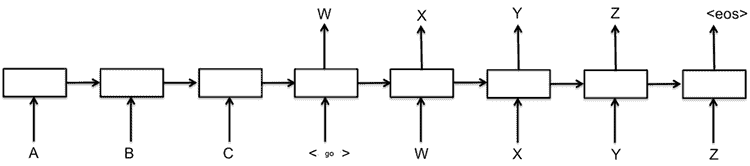
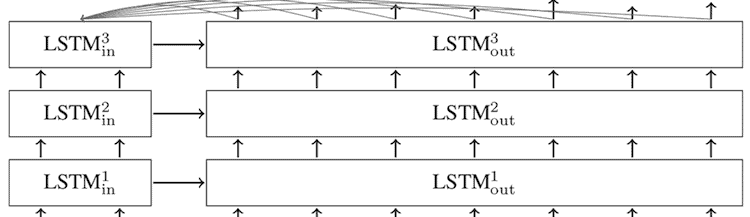
With this model, you have a choice for each RNN. A standard option is LSTM cells, where LSTM stands for long short-term memory. Citing The Ubuntu Dialogue Corpus:
“LSTMs were introduced in order to model longer-term dependencies. This is accomplished using a series of gates that determine whether a new input should be remembered, forgotten (and the old value retained), or used as output. The error signal can now be fed back indefinitely into the gates of the LSTM unit. This helps overcome the vanishing and exploding gradient problems in standard RNNs, where the error gradients would otherwise decrease or increase at an exponential rate.”
For a discussion of other possibilities (standard RNN or TF-IDF) see6, and Table 4 for a comparison of the different choices available.
Another possible architecture is Dual Encoder described in Deep Learning for chatbots.
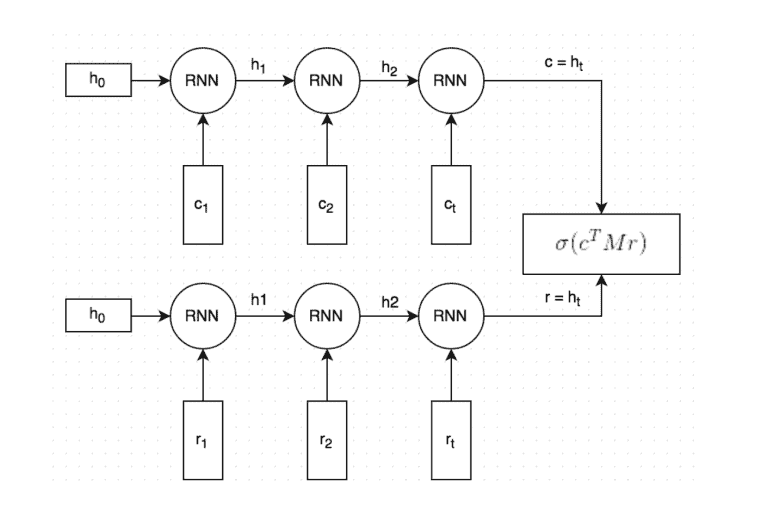
Here’s how it works:
- Both the context and the answer are turned into vectors (vectors of vectors of words). This conversion occurs during the data processing phase.
- Both vectors (“embedded words”) are put into the RNN word-by-word. This gives other vectors which capture the meaning of the context and the answer (They are referred to as c for context and a for an answer). You decide how large those vectors should be.
- Vector c is multiplied with some matrix M to produce an answer a. The matrix M is learned during training (your weights).
- The predicted answer is then compared to the actual answer to measure its accuracy. The programmer applies regularisation functions (e.g., sigmoid) to convert the measurement into an actual probability.
Of course, this is just a tip of an iceberg. Having an architecture is one thing, but tuning it to work well with our problem is a completely different issue. This is also very time consuming and needs to be dealt with care.
You can also classify chatbots into vertical and horizontal types. Vertical chatbots are closed-domain chatbots focused on a particular application: this would be the case with a chatbot for a customer service department in the telecom industry. A horizontal chatbot is a general and open-domain bot like Siri, Alexa or Google Assistant. Because of its more specific context and vocabulary, a vertical chatbot is easier to build than a horizontal one.
One of the issues you will run into with vertical chatbots is the out-of-vocabulary problem. To fix this, you will need to supply your training set with all of the technical terms relevant to your business/application. However, in general, the seq2seq provides a simple way to build unsupervised vertical chatbots. (Unsupervised Deep Learning for Vertical Conversational Chatbots).
Conclusion
Chatbots are a wonderful customer service solution for companies that are inundated with requests every day and cannot afford to maintain an entire customer service department. Though it may require an initial investment and some outsourcing to get the system installed correctly, implementing chatbots will ultimately cut costs in the long term, and give customers the 24/7 availability and freedom to connect with your company, improving the customer experience and increasing satisfaction. And that’s the most important thing of all.
If you are interested in adding chatbots to your customer service initiatives and need help with the next step, get in touch with us here.
If you are interested in adding chatbots to your customer service initiatives and need help with the next step, get in touch with us here.
We are here to help your business grow.
References:
- Smart Reply (Google) https://arxiv.org/pdf/1606.04870.pdf
- seq2seq tutorial: https://www.tensorflow.org/tutorials/seq2seq
- word2vec: https://code.google.com/archive/p/word2vec/
- http://www.wildml.com/2016/07/deep-learning-for-chatbots-2-retrieval-based-model-tensorflow/
- https://chatbotsmagazine.com/unsupervised-deep-learning-for-vertical-conversational-chatbots-c66f21b1e0f
- https://arxiv.org/pdf/1506.08909.pdf


