
Introduction
How do you teach a machine to draw a human face if it has never seen one? A computer can store petabytes of photos, but it has no idea what gives a bunch of pixels a meaning related to someone’s appearance.
For many years this problem has been tackled by various generative models. They used different assumptions, often too strong to be practical, to model the underlying distribution of the data.
The results were suboptimal for most of the tasks we have now. Text generated with Hidden Markov Models was very dull and predictable, images from Variational Autoencoders were blurry and, despite the name, lacked variety. All those shortcomings called for an entirely new approach, and recently such a method was invented.
In this article, we aim to give a comprehensive introduction to general ideas behind Generative Adversarial Networks (GANs), show you the main architectures that would be good starting points and provide you with an armory of tricks that would significantly improve your results.
Towards the invention of GANs
The basic idea of a generative model is to take a collection of training examples and form a representation of their probability distribution. And the usual method for it was to infer a probability density function directly.
When I was studying generative models the first time I couldn’t help but wonder: why bother with them when we have so many real life training examples already? The answer was quite compelling, here are just a few of possible applications that call for a good generative model:
- Simulate possible outcomes of an experiment, cutting costs and speeding up the research.
- Action planning using predicted future states: imagine a GAN that “knows” the road situation the next moment.
- Generating missing data and labels: we often lack the clean data in the right format, and it causes overfitting.
- High-quality speech generation
- Automated quality improvement for photos (Image Super-Resolution)
In 2014, Ian Goodfellow and his colleagues from the University of Montreal introduced Generative Adversarial Networks (GANs). It was a novel method of learning an underlying distribution of the data that allowed generating artificial objects that looked strikingly similar to those from real life.
The idea behind the GANs is very straightforward. Two networks, a Generator and a Discriminator, play a game against each other. The objective of the Generator is to produce an object, say, a picture of a person, that would look like a real one. The goal of the Discriminator is to be able to tell the difference between generated and real images.
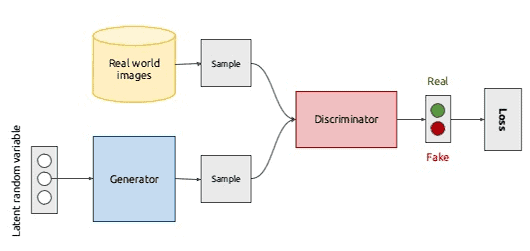
This illustration gives a rough overview of the Generative Adversarial Network. For the moment it’s most important to understand that the GAN is rather a way to make two networks work together, and both Generator and Discriminator have their own architecture. To better understand where this idea came from we will need to recall some basic algebra and ask ourselves: how can we fool a neural network that classifies images better than most humans?
Adversarial examples
Before we get to describing GANs in details, let’s take a look at a similar topic. Given a trained classifier, can we generate a sample that would fool the network? And if we do, how would it look like?
It turns out, we can.
Even more: for virtually any given image classifier it’s possible to morph an image into another, which would be misclassified with high confidence while being visually indistinguishable from the original! Such a process is called an adversarial attack, and the simplicity of the generating method explains quite a lot about GANs. An adversarial example is an example carefully computed with the purpose to be misclassified. Here is an illustration of this process. The panda on the left is indistinguishable from the one on the right, and yet it’s classified as a gibbon.
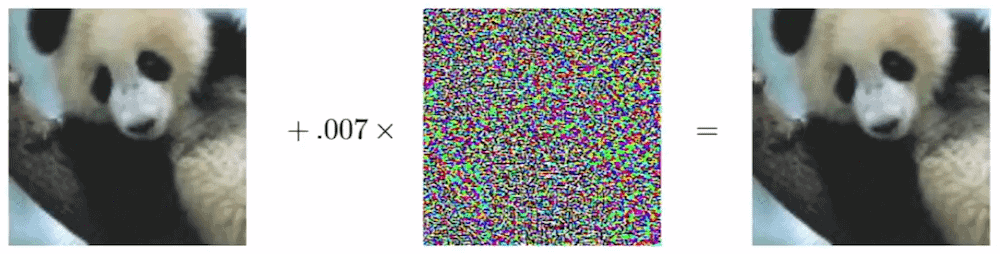
An image classifier is essentially a complex decision boundary in a high-dimensional space. Of course, when it comes to classifying the images, we can’t draw this boundary. But what we can safely assume is that when the training is over, the network is not generalized for all images, only for those we had in the training set. Such generalization is likely not a good approximation of real life. In other words, it overfits to our data, and we are going to exploit it.
Let’s start adding random noise to the image and keep it very close to zero. We can achieve that by controlling L2 norm of the noise. Mathematical notation shouldn’t worry you: for all practical purposes you can think of L2 norm as the length of a vector. The trick here is the more pixels you have in an image, the bigger its average L2 norm is. So, if the norm of your noise is sufficiently low, you can expect it to be visually imperceptible, while the corrupted image will be very far from the original in the vector space.
Why is that so?
Well, if the HxW image is a vector, then HxW noise that we add to it is also a vector. The original image has all kinds of colors which are rather intensive. That increases the L2 norm. The noise, on the other hand, is a visually chaotic set of rather pale pixels, a vector with small norm. At the end we add them together, getting a new vector for the corrupted image which is comparatively close to the original, and yet misclassified!
Now, if the decision boundary for the original class Dog is not that far (in terms of L2 norm), this additive noise puts the new image outside of the decision boundary.
You don’t need to be a world class topologist to understand manifolds or decision boundaries of certain classes. As each image is just a vector in a high-dimensional space, a classifier trained on them defines “all monkeys” as “all image vectors in this high-dimensional blob that is described by hidden parameters”. We refer to that blob as the decision boundary for the class.
Okay, so, you are saying we can easily fool a network by adding random noise. What does it have to do with generating new images?
Generator and Discriminator
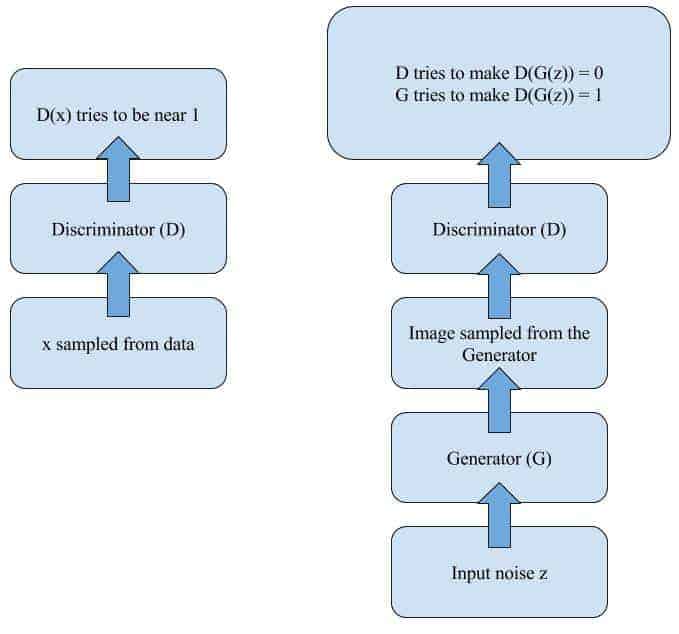
Now that we have a grasp of adversarial examples, we are one step away from the GANs! So, what if instead of the classifier in the previous part we had a network designed only for two classes: “genuine” and “fake”? Following the notation used in the original paper by Goodfellow et al., we will call it a Discriminator.
Let’s add another network that will learn to generate fake images that Discriminator would misclassify as “genuine.” The procedure will be exactly like the one we have used in Adversarial examples part. This network is called Generator, and the process of adversarial training gives it fascinating properties.
On every step of training we feed the Discriminator a bunch of images from the training set and a bunch of fake ones, so it gets better and better at distinguishing them. As you remember from statistical learning theory, that essentially means learning the underlying distribution of data.
So, what does it take to fool a Discriminator later on, when it becomes really good at spotting fake images? That’s right! To learn how to generate compelling fakes.
There’s an old but brilliant mathematical result (Minimax theorem) that started the game theory as we know it and states that for two players in a zero-sum game the minimax solution is the same as the Nash equilibrium.
Woah, that’s a mouthful!
In simpler terms, when two players (D and G) are competing against each other (zero-sum game), and both play optimally, assuming that their opponent is also playing optimally (minimax strategy), the outcome is predetermined and none of the players can change it (Nash equilibrium).
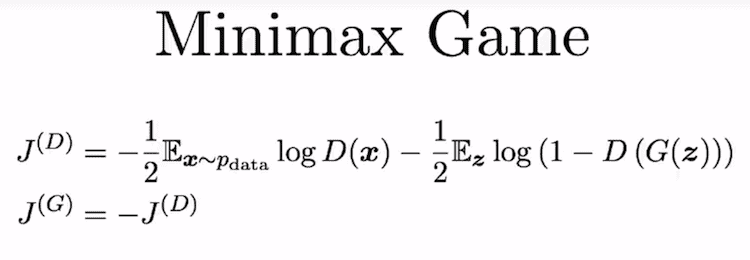
So, for our networks, it means that if we train them long enough, the Generator will learn how to sample from true “distribution,” meaning that it will start generating real life-like images, and the Discriminator will not be able to tell fake ones from genuine ones.
Best architectures to start with
When it comes to practice, especially in Machine Learning, many things just stop working. Luckily, we have gathered some useful tips for achieving better results. In this article, we will start with reviewing some classic architectures and providing links to them.
Deep Convolutional Generative Adversarial Network (DCGAN)
For about a year after the first paper, training GANs resembled art rather than science: the models were unstable and required a bunch of hacks to work. In 2016 Radford et al. published the paper titled “Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks” describing the model that subsequently became famous as DCGAN.
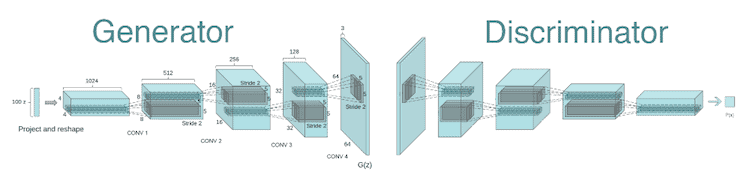
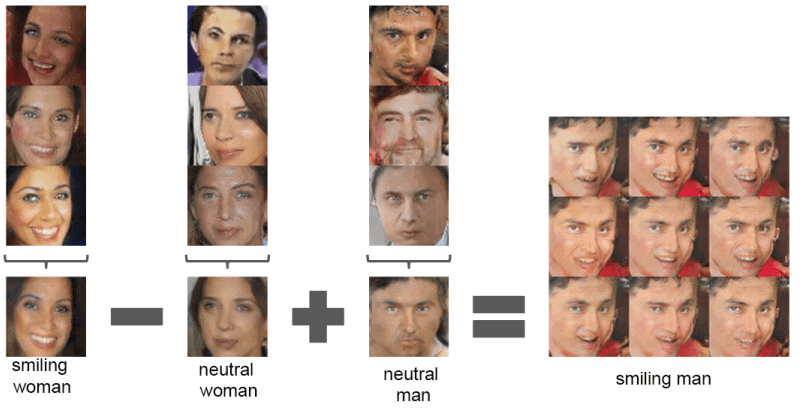
The most remarkable thing about DCGAN was that this architecture was stable in most settings. It was one of the first papers to show vector arithmetic as an intrinsic property of the representations learned by the Generator: it’s the same trick as with the word vectors in Word2Vec, but with images!
DCGAN is the simplest stable go-to model that we recommend to start with. We will add useful tips for training/implementation along with links to code examples further.
Conditional GAN
This extension of the GAN meta-architecture was proposed to improve the quality of generated images, and you would be 100% right to call it just a smart trick. The idea is that if you have labels for some data points, you can use them to help the network build salient representations. It doesn’t matter what architecture you use: the extension is the same every time. All you need to do is to add another input to the Generator.
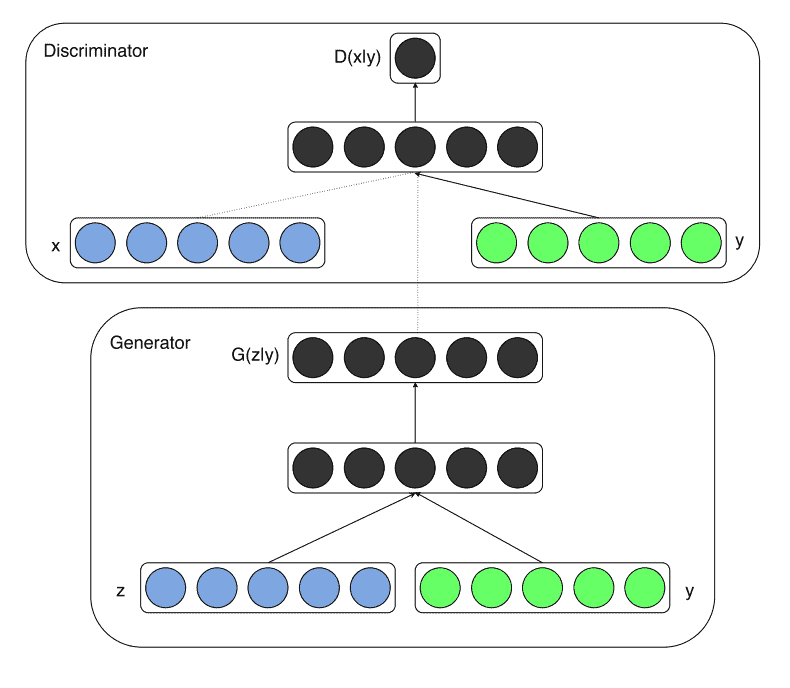
So, what happens now? Let’s say your model can generate all kinds of animals, but you are really fond of cats. Instead of passing generated noise into the Generator and hoping for the best, you add a few labels to the second input, for example as the id of a class cat or just as word vectors. In this case, the Generator is said to be conditioned on the class of expected input.
Tips and tricks
When it comes to practice, the descriptions you read in the papers are not enough. Same for tutorials that give you an introductory view of an algorithm: more often their approach works only on the toy dataset they use for demonstration. In this article, we are aiming to provide you with a set of tools that will give you the ability to start your own research on GANs or just building your own cool stuff right away.
So, you have implemented your own GAN or just cloned one from GitHub (which is a development style I honestly can get behind!). There’s no consensus on which flavor of SGD works better, so the best way would be to use your favorite (I use Adam) and carefully tune the learning rate before you commit to prolonged training (it will save you a lot of time). The general workflow looks very straightforward:
- Sample a minibatch of training examples and compute the Discriminator scorings for them
- Generate a minibatch of samples and compute the Discriminator scorings for them
- Perform an update using the accumulated gradients from both steps
It’s essential to process training and generated minibatches separately and compute the batch norms for different batches individually: doing that ensures fast initial training of the Discriminator.
Here’s an illustration of the correct way to form minibatches:
Sometimes it’s better to perform more than one step for Discriminator per every step of a Generator, so if your Generator starts “winning” in terms of a loss function, consider doing this.
If you use BatchNorm layers in a Generator, it can cause strong intra-batch correlation, which you can see in the next figure:
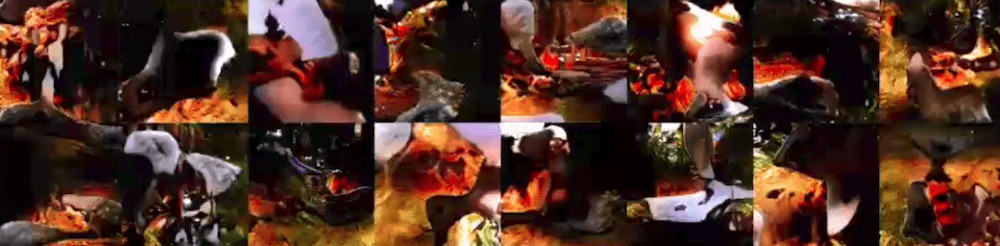
Essentially, every batch will be producing the same thing with slight variations. How do you prevent that? One way would be to precompute the mean pixel and standard deviation and just use it every time, but it causes overfitting very often. Instead, there’s a neat trick called Virtual Batch Normalization: predefine a batch before you start training (let’s call it R as in Reference), and for each new batch X compute the normalization parameters using the concatenation of R and X.
Another interesting trick is to sample the input noise from a sphere rather than from a cube. An approximation of this can be achieved just by controlling the norm of a noise vector, but the real uniform sampling from a high-dimensional cube is preferable.
The next trick is to avoid using sparse gradients, especially in the Generator. That can be achieved just by swapping certain layers to their “smooth” analogs, e.g.:
- ReLU -> LeakyReLU
- MaxPooling -> AvgPooling, Convolution + stride
- Unpooling -> Deconvolution
Conclusion
In this article, we gave an explanation of Generative Adversarial Networks along with practical tips for implementation and training. In the resources section, you will find the implementations of GANs which will help you to start your experiments.
In the upcoming posts, we plan to discuss advanced architectures and recent developments in GANs. Are you interested in how neural networks help to discover new drugs and prolong our lives? Stay tuned!
Resources
Lectures
- Generative Adversarial Networks @ NIPS 2016 by Ian Goodfellow
- Adversarial Examples and Adversarial Training by Ian Goodfellow
- How to train a GAN @ NIPS 2016 by Soumith Chintala
Tutorials
- Extensive tutorial from O’Reilly: GANs for beginners
- Minimalistic tutorial with lots of room to implement the hacks
Repositories
Papers
- Generative Adversarial Networks
- Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
- Conditional Generative Adversarial Nets
The article by Roman Trusov


